[论文解读] Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
这篇论文提出 MAFT,一种面向 CLIP 的掩码感知微调框架,使掩码提案具有可区分性,在提升零样本分割的同时保持可迁移性。
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP's zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. The code is available at https://github.com/jiaosiyu1999/MAFT.git.
研究动机与目标
- 解决冻结的 CLIP 在零样本分割中对不同掩码提案不敏感的问题。
- 开发一种掩码感知的微调方法,保持 CLIP 的可迁移性。
- 实现 MAFT 与现有冻结 CLIP 分割流程的高效即插即用集成。
提出的方法
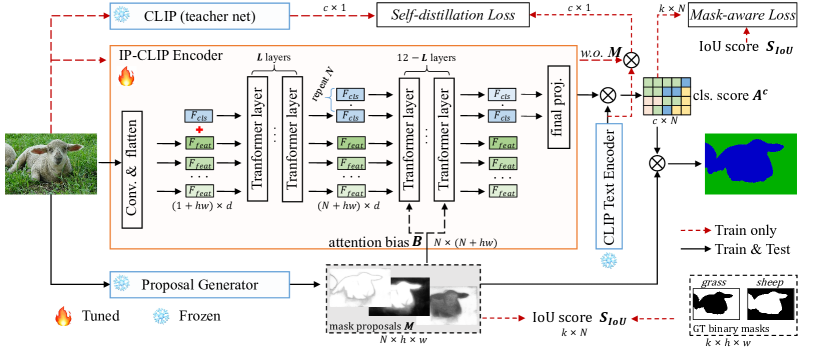
- 引入图像-提案 CLIP 编码器(IP-CLIP 编码器),通过掩码多头注意力处理任意数量的图像和掩码提案。
- 设计掩码感知损失,将 CLIP 预测的提案分数与基于 IoU 的质量信号对齐。
- 引入自蒸馏损失,通过将 IP-CLIP 的输出与冻结的 CLIP 教师对齐来维持 CLIP 的零样本迁移能力。
- 仅微调 IP-CLIP 编码器(保留提案生成器和 CLIP 文本编码器冻结)在一个轻量级的 MAFT 过程中。
- 提供一种可插拔的方法,可添加到现有冻结 CLIP 的零样本分割方法中。
- 展示在不同主干网络和开放词汇设置下的鲁棒性。

实验结果
研究问题
- RQ1CLIP 对掩码提案的敏感性如何影响零样本分割性能?
- RQ2掩码感知的微调方案是否能够在不牺牲迁移性的情况下改进提案分类?
- RQ3IP-CLIP 编码器是否能够高效处理任意数量的提案?
- RQ4MAFT 是否在标准零样本分割基准和开放词汇设置下提升性能?
主要发现
- 将 MAFT 集成到现有方法时,可以显著提升未见类别的 mIoU,在标准基准上。
- 带掩码感知训练的 IP-CLIP 编码器通过使 CLIP 对不同提案有不同响应来降低误报。
- 自蒸馏在实现掩码感知微调的同时保持迁移性。
- MAFT 兼容多种 CLIP 主干,并且可以扩展到开放词汇分割,带来显著提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。