[论文解读] LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
LIBERO 引入一个可扩展的、用于机器人操作终身学习的程序化生成基准,评估知识迁移、架构、算法和预训练,在四个任务套件的130个任务中进行评估。
Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, no single visual encoder architecture excels at all types of knowledge transfer, and naive supervised pretraining can hinder agents' performance in the subsequent LLDM. Check the website at https://libero-project.github.io for the code and the datasets.
研究动机与目标
- 研究决策制定中终身学习的动机,其中需要迁移陈述性和过程性知识。
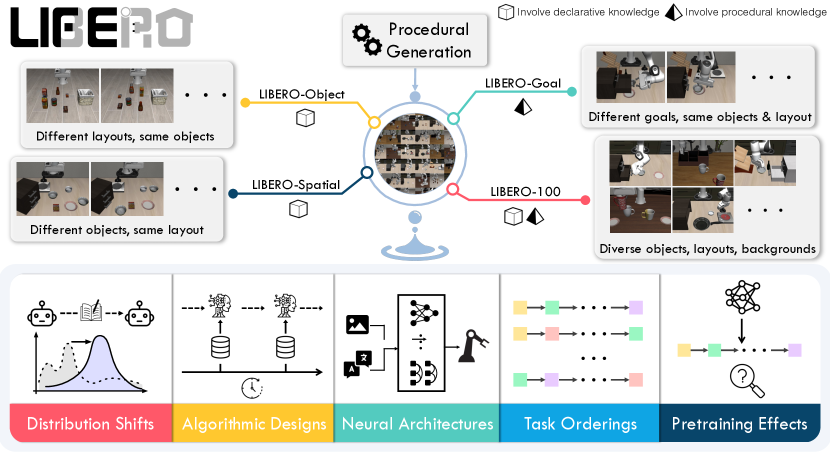
- 提供一个可扩展的任务生成管道,以创建多样化、语言条件的机器人操作任务。
- 系统性评估策略架构、终身学习算法和预训练对前向和后向迁移的影响。
- 分析对任务排序的鲁棒性以及语言嵌入在 LLDM 表现中的作用。
提出的方法
- 通过从 Ego4D 语言注释中提取行为模板并将其编码到 PDDL 中,程序化生成无尽的机器人操作任务。
- 视频基础的语言条件任务指令与场景布局和初始对象配置配对。
- 评估四个任务套件(LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-100)以及130个任务在多种策略和 LL 算法上的表现。
- 使用行为克隆在从远程操作中收集的演示上训练策略,以实现样本高效的基准测试。
- 在学习新任务时排除对前一个任务的访问,以模拟终身学习的约束。
实验结果
研究问题
- RQ1不同神经架构和终身学习算法在各种分布移位下的表现如何?
- RQ2架构选择对 LLDM 中知识迁移,特别是空间、对象和目标知识的影响是什么?
- RQ3现有的来自监督学习文献的终身学习方法是否能有效转化到机器人领域的 LLDM?
- RQ4语言嵌入质量或任务标识符编码是否影响 LLDM 的表现?
- RQ5LLDM 方法对不同任务顺序和预训练的鲁棒性如何?
主要发现
- 序列微调(SeqL)在前向迁移方面在大多数任务套件中表现最佳,常常优于专门的 LL 算法。
- ER(回忆)在所有任务套件上都具有鲁棒性,通常在之前学过的任务上保持性能,在多种情境下优于其他方法。
- PackNet(动态架构)在 LIBERO-X(对象/空间多样性)表现出色,但在 LIBERO-Long 上因容量有限而表现不佳。
- 基于 ViT 的架构(ViT-T)和时序处理的变换器总体上在许多任务上优于 ResNet-RNN,架构效应随 LL 算法而异。
- 语言嵌入(BERT、CLIP、GPT-2、Task-ID)在 LIBERO-Long 中没有统计显著的差异,这表明当前嵌入对任务标识符的作用类似于词袋。
- 基础的监督性预训练可能对下游的 LLDM 性能有负面影响,提示需要更谨慎的预训练策略。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。