[论文解读] LIMA: Less Is More for Alignment
一个65B规模的 LLaMa 模型在 1,000 条精心挑选的提示/回答上进行微调(无 RLHF),在人工评估中往往达到或超过基线,表明预训练在小规模指令微调之外仍占主导地位。
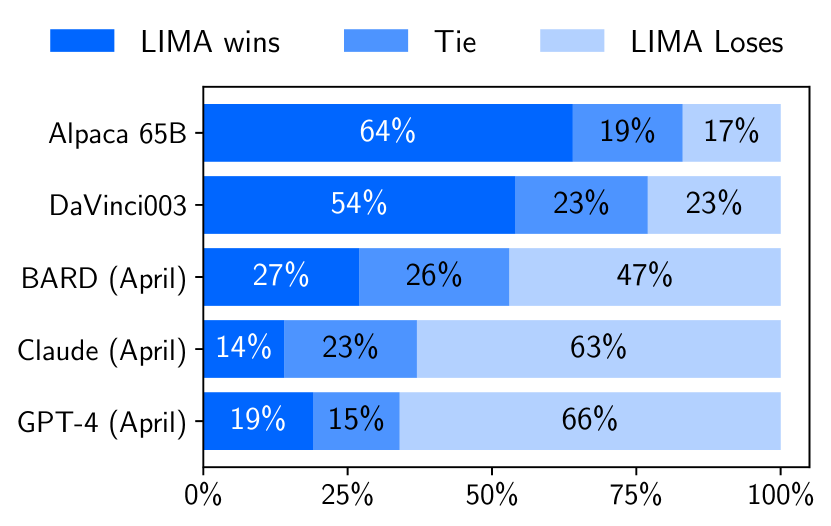
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
研究动机与目标
- 证明一个强大的预训练语言模型在仅有 1,000 条高质量示例且不使用 RLHF 或人类偏好建模的情况下也能被有效对齐。
- 通过将 LIMA 与最先进基线进行对比评估,测试对齐是否主要依赖于预训练而非指令微调。
- 研究对齐数据中的数据多样性和质量与数量的关系,并评估多轮对话能力。
提出的方法
- 在 1,000 条示例(其中 750 条来自社区来源,250 条由人工撰写)上,使用标准监督损失对 65B 参数的 LLaMa 模型(LLaMa-65B)进行微调。
- 在微调过程中引入一个特殊的端末符号,用以区分用户/助手轮次。
- 在 300 个提示中,比较 LIMA 与 RLHF 调整和其他基线在人工偏好及 GPT-4+ 标注者试验中的表现。
- 使用 7B 模型对数据多样性、质量和数量进行消融分析,以隔离各因素的影响。
- 在零样本和扩展对话链的情境下评估多轮对话能力。
- 使用少量与安全相关的提示评估安全行为并分析失败模式。

实验结果
研究问题
- RQ1是否可以仅用 1,000 条示例在不使用 RLHF 或偏好建模的情况下有效对齐一个预训练的大型语言模型?
- RQ2数据多样性和质量相对于数量的影响对对齐性能有多大?
- RQ3少量经过策划的对话数据在多轮对话能力上能提升到何种程度?
- RQ4在人工评估和基于 GPT-4 的评估中,LIMA 相对于最前沿的对齐模型表现如何?
主要发现
- 在人工评估和 GPT-4 标注者评估下,LIMA 的表现与 DaVinci003 和 Alpaca 相当。
- 在绝对质量评估中,约有一半的 LIMA 输出被评为优秀。
- 仅增加数据数量在没有提升提示多样性和数据质量的情况下收益递减。
- 增加 30 条手工制作的对话链显著提升多轮对话质量(从 45.2% 提升到 76.1% 的优秀率)。
- 即使没有对话数据,LIMA 的连贯多轮对话也能出现,但质量随针对性对话增强而提升。
- 在安全性提示上,LIMA 对 80% 的案例给出安全回应,且训练中使用了一个小型的安全聚焦子集。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。