[论文解读] LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation
本论文提出 LLM4DV,一种基准框架,使用提示的大语言模型生成硬件测试刺激,在三个 DUT 模块上评估,在较简单设计上显示出有前景的覆盖率,但在完整CPU上的收益有限。
Hardware design verification (DV) is a process that checks the functional equivalence of a hardware design against its specifications, improving hardware reliability and robustness. A key task in the DV process is the test stimuli generation, which creates a set of conditions or inputs for testing. These test conditions are often complex and specific to the given hardware design, requiring substantial human engineering effort to optimize. We seek a solution of automated and efficient testing for arbitrary hardware designs that takes advantage of large language models (LLMs). LLMs have already shown promising results for improving hardware design automation, but remain under-explored for hardware DV. In this paper, we propose an open-source benchmarking framework named LLM4DV that efficiently orchestrates LLMs for automated hardware test stimuli generation. Our analysis evaluates six different LLMs involving six prompting improvements over eight hardware designs and provides insight for future work on LLMs development for efficient automated DV.
研究动机与目标
- 通过利用 LLMs 生成测试刺激来减少硬件设计验证中的人工工作量。
- 为设计验证任务创建可重复使用的基准框架(LLM4DV)。
- 推广提示工程技巧,以改进基于 LLM 的测试刺激生成。
- 提供开源的 DUT 模块和框架,供研究人员实验基于 LLM 的 DV。
提出的方法
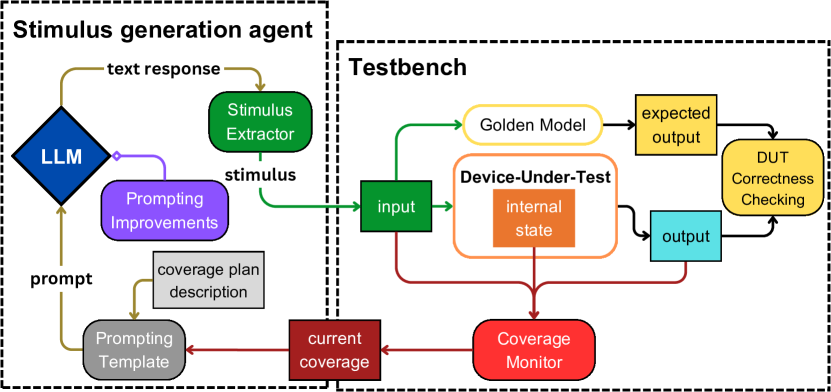
- 设计一个刺激生成代理,与 DUT 和覆盖率监控交互。
- 开发一个包含系统消息、初始与迭代查询的 Coverage-Feedback 模板。
- 提出四种提示改进:missed-bin 采样、best-iterative-message 采样、对话重启,以及 best-iterative-message 缓冲区重置。
- 使用 GPT-3.5-turbo-0613(以及 Llama 2 的消融实验)在固定的 token 限额内生成刺激。
- 在三个 DUT 上对比传统约束随机测试(CRT):Primitive Data Prefetcher Core、Ibex Instruction Decoder 和 Ibex CPU。
实验结果
研究问题
- RQ1相较于 CRT,基于 LLM 的 Stimulus Generation Agent 能否在硬件 DUT 上实现高覆盖率?
- RQ2哪些提示策略最有效地引导 LLM 触达 DV 任务中的覆盖区间?
- RQ3任务复杂度如何影响 LLM 驱动的测试刺激在不同 DUT 上的有效性?
- RQ4在全 CPU 规模设计中,LLMs 生成刺激的局限性是什么?
主要发现
| Config | DUT 模块 | 最大覆盖率 | 最大覆盖率率 | 平均消息/尝试 | 消息/尝试 的标准差 |
|---|---|---|---|---|---|
| Random | Primitive Data Prefetcher Core | 4 | 0.39% | - | - |
| A1 | Primitive Data Prefetcher Core | 987 | 95.45% | 641 | 104.24 |
| A2 | Primitive Data Prefetcher Core | 1023 | 98.94% | 617.5 | 165.06 |
| A3 | Primitive Data Prefetcher Core | 1007 | 97.39% | 459.33 | 287.21 |
| Random | Ibex CPU Instruction Decoder | 1136 | 53.92% | - | - |
| B1 | Ibex CPU Instruction Decoder | 1695 | 80.45% | 864 | 147.92 |
| B2 | Ibex CPU Instruction Decoder | 1816 | 86.19% | 844.25 | 127.94 |
| Random | Ibex CPU | 3 | 1.53% | - | - |
| C1 | Ibex CPU | 10 | 5.10% | 42.49 | 11.74 |
| C2 | Ibex CPU | 11 | 5.61% | 45.72 | 16.17 |
- LLM4DV 在较简单的 DUT 上可以实现高覆盖率,例如 Primitive Data Prefetcher Core 在最佳配置下达到 98.94%。
- Ibex Instruction Decoder 在最佳配置下达到 86.19% 覆盖率。
- 对于完整的 Ibex CPU,框架在最佳设置下实现了 5.61% 覆盖率,相对而言仍然优于 CRT。
- 四种提示改进显著影响性能,某些 DUT 的配置甚至接近 100% 的覆盖率。
- 开放源代码框架和 DUT 以促进社区实验。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。