[论文解读] LoRA+: Efficient Low Rank Adaptation of Large Models
LoRA+ 通过对适配矩阵使用非对称学习率来改进低秩自适应(LoRA),实现1-2%的性能提升,finetuning速度提升至约2x且不增加额外计算成本。
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $\%$ improvements) and finetuning speed (up to $\sim$ 2X SpeedUp), at the same computational cost as LoRA.
研究动机与目标
- 动机与诊断在宽模型上标准 LoRA 的微调不理想之处,原因是 A 和 B 适配器采用相同学习率。
- 提出基于无穷宽度缩放论证的固定比值的原理性学习率缩放,适用于 LoRA 适配器 A 与 B。
- 展示在语言模型及任务上的微调性能和速度的提升。
- 在现实应用中为 LoRA+ 的比值选择和工作区间提供实际可操作的指南。
提出的方法
- 如同标准 LoRA 一样引入 LoRA 适配器 W = W* + (alpha/r) B A,并在无穷宽极限下分析训练动力学。
- 证明对 A 和 B 使用相同学习率在宽模型上是次优的,并推导一个固定比值使得 eta_A = Theta(n^{-1}) 且 eta_B = Theta(1)。
- 基于网络宽度建立理论缩放论证,以确保稳定且高效的特征学习(Delta f_t = Theta(1))。
- 用简易线性与非线性模型以及对语言模型微调的广泛实验来验证理论。
- 将 LoRA+ 与标准 LoRA 进行对比,在相同计算成本下报告性能提升(1-2%)和微调速度提升(最高约 2x)。
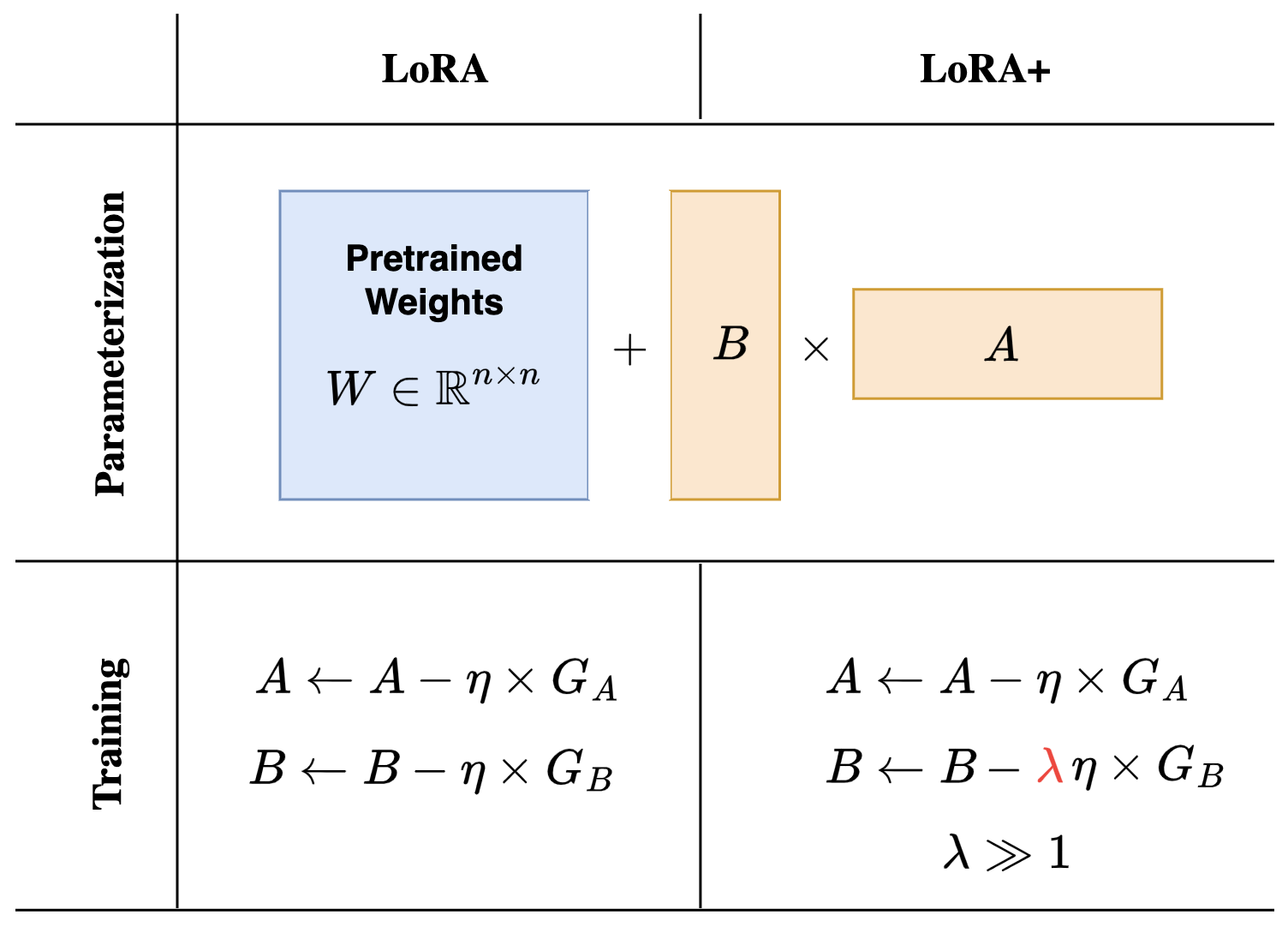
实验结果
研究问题
- RQ1当模型宽度增大时,LoRA 适配器 A 与 B 的学习率相同是否会阻碍特征学习?
- RQ2是否存在一个原理性的 eta_A 与 eta_B 学习率之比,能够在无穷宽度条件下恢复高效微调?
- RQ3所提出的缩放规则是否在语言模型与任务上改善实际微调的性能与速度?
- RQ4在现实应用中为固定 eta_B/eta_A 比例选择提供哪些指南?
主要发现
- 对于宽模型,采用 A 与 B 相同学习率的标准 LoRA 效率低下。
- 一个原理性设定:eta_A = Theta(n^{-1}) 且 eta_B = Theta(1) 能带来稳定高效的 LoRA 微调(Delta Z_B^t = Theta(1))。
- LoRA+ 在与 LoRA 相同计算成本下实现 1-2% 的性能提升和最高 2x 的微调加速。
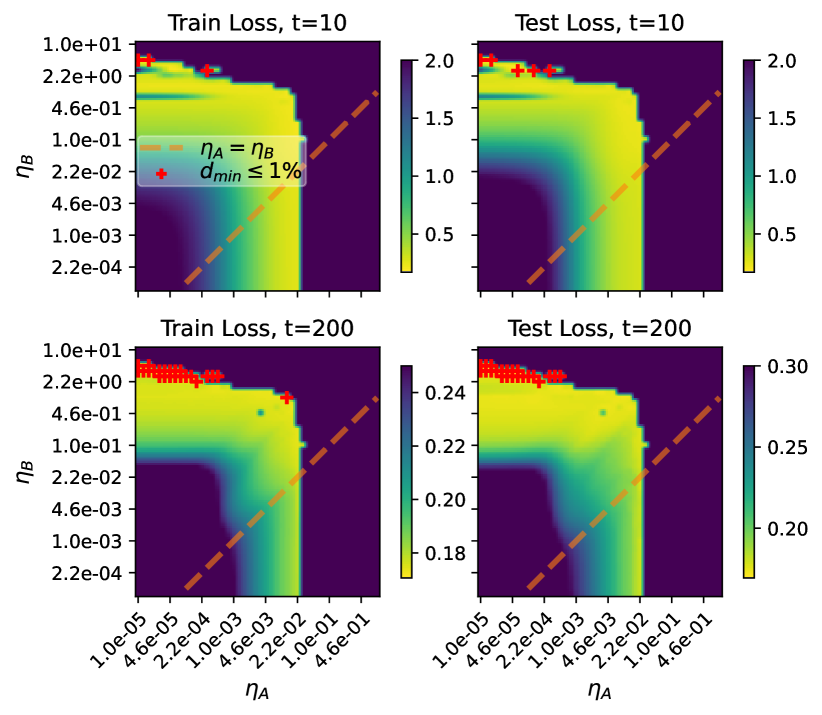
- 简易模型和神经网络实验表明,通常 eta_B >> eta_A 能带来近似最优的损失和稳定的特征学习。
- 该方法为选择固定的 eta_B/eta_A 比例以简化超参数调优同时保持效率提供指导。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。