[论文解读] Low-Resource Named Entity Recognition with Cross-Lingual, Character-Level Neural Conditional Random Fields
本文提出一种跨语言、字符级神经CRF用于命名实体识别(NER),将相关资源丰富语言的知识迁移到资源匮乏的语言,在迁移设置下显著提升F1分数,相较基线更优。
Low-resource named entity recognition is still an open problem in NLP. Most state-of-the-art systems require tens of thousands of annotated sentences in order to obtain high performance. However, for most of the world's languages, it is unfeasible to obtain such annotation. In this paper, we present a transfer learning scheme, whereby we train character-level neural CRFs to predict named entities for both high-resource languages and low resource languages jointly. Learning character representations for multiple related languages allows transfer among the languages, improving F1 by up to 9.8 points over a loglinear CRF baseline.
研究动机与目标
- 解释NER对大量数据的需求挑战以及需要有效的低资源方法。
- 提出一个具有共享字符级表示的跨语言神经CRF,以实现相关语言之间的迁移。
- 在15种语言上评估迁移学习,以评估在低资源情境下的性能提升。
提出的方法
- 定义一个基于CRF的NER序列标注模型,具有9个实体标签(每种类型的B/I和O)。
- 将基于对数线性特征的CRF与使用字符级LSTM加词嵌入的神经CRF进行比较。
- 通过在语言之间绑定字符编码器来引入跨语言共享,同时保持语言特有的词嵌入。
- 将语言ID嵌入和通过共享转移及神经势中的tanh交互实现跨语言投影。
- 使用一个联合目标训练,包含目标语言数据以及源语言数据的加权和(mu控制迁移强度)。
- 在 Pan et al. (2017) 的15种语言上评估,使用100-shot低资源和10k高资源设置进行迁移。
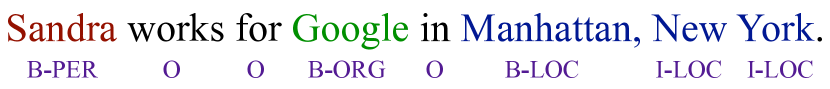
实验结果
研究问题
- RQ1字符级神经CRF是否能跨相关语言泛化命名实体表示?
- RQ2跨语言迁移是否在低资源场景中提升NER性能,与单语言基线相比如何?
- RQ3单一源语言与多源语言对迁移效果的影响是什么?
主要发现
- 在高资源单语言设置中,神经CRF的表现优于对数线性CRF。
- 在低资源单语言设置中,对数线性CRF优于神经CRF。
- 通过跨语言迁移,神经CRF在F1上优于对数线性基线,表明跨语言抽象能力更强。
- 使用源语言(如西班牙语、加泰罗尼亚语、意大利语)的迁移,在低资源目标上为神经CRF带来显著的F1提升。
- 在高资源目标设置中,迁移几乎没有提升。
- 在15种语言中,带跨语言迁移的神经CRF缩小了与高资源表现的差距,尽管仍有提升空间。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。