[论文解读] Machine Learning with a Reject Option: A survey
本综述对带拒绝选项的机器学习进行了全面综述,形式化模糊性与新颖性拒绝、架构、评估方法、学习方法,以及与相关领域的联系。
Machine learning models always make a prediction, even when it is likely to be inaccurate. This behavior should be avoided in many decision support applications, where mistakes can have severe consequences. Albeit already studied in 1970, machine learning with rejection recently gained interest. This machine learning subfield enables machine learning models to abstain from making a prediction when likely to make a mistake. This survey aims to provide an overview on machine learning with rejection. We introduce the conditions leading to two types of rejection, ambiguity and novelty rejection, which we carefully formalize. Moreover, we review and categorize strategies to evaluate a model's predictive and rejective quality. Additionally, we define the existing architectures for models with rejection and describe the standard techniques for learning such models. Finally, we provide examples of relevant application domains and show how machine learning with rejection relates to other machine learning research areas.
研究动机与目标
- 形式化预测模型中放弃预测的条件(模糊性与新颖性)。
- 评审并对能够实现拒绝的架构和学习策略进行分类。
- 概述具有拒绝能力模型的评估框架与成本。
- 解释如何结合多个拒绝器,并将拒绝与更广泛的机器学习主题联系起来。
- 突出在可信ML及相关领域的应用与未来方向。
提出的方法
- 定义带拒绝的学习问题,并将输出空间扩展为包含一个拒绝符号。
- 将拒绝分类为模糊性拒绝与新颖性拒绝,并给出偏差-方差与数据分布的解释。
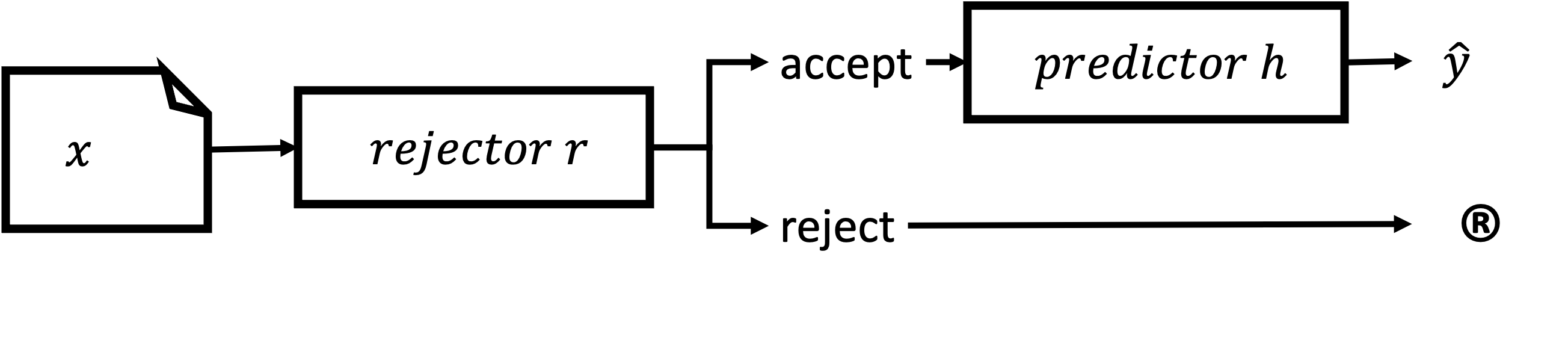
- 回顾架构(分离的、相关的、整合的)及在预测中如何实现拒绝。
- 总结评估方法:固定拒绝率、权衡曲线(ARC/AURC)和基于成本的指标。
- 描述拒绝器的学习策略(密度估计、一类分类器、新颖性分数、置信函数)。
- 讨论多个拒绝器的整合与组合,以及与不确定性量化、主动学习及相关领域的联系。
实验结果
研究问题
- RQ1如何将模型应何时放弃预测(模糊性 vs. 新颖性)形式化?
- RQ2如何评估预测与拒绝质量,包括权衡与成本?
- RQ3哪些架构能实现拒绝,以及如何学习带拒绝的模型?
- RQ4分离、相关和综合拒绝器各自的优缺点是什么?
- RQ5如何组合多个拒绝器及其与其他机器学习研究领域的关系?
主要发现
- 提供了对拒绝类型的结构化分类(模糊性与新颖性)以及三大架构族(分离的、相关的、整合的)的分类。
- 概述了包括固定拒绝率、ARC/AURC权衡和基于成本的指标在内的全面评估框架。
- 详细介绍拒绝器的学习范式(密度/概率估计、一类方法、新颖性分数、置信函数)。
- 展示拒绝在部署中如何在平衡预测质量和覆盖率的同时提升信任、安全和公平性。
- 将拒绝与不确定性量化、异常检测、主动学习、元学习及相关领域联系起来。
- 讨论应用的实际考虑因素并概述未来研究方向。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。