[论文解读] MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
本论文提出 MambaMixer,一种双通道与双令牌选择的状态空间模型块,构建 Vision MambaMixer (ViM2) 和 Time Series MambaMixer (TSM2),在长序列上以线性复杂度实现具有竞争力或更优的性能。
Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
研究动机与目标
- 推动在超越二次方注意力 Transformer 的可扩展长序列建模。
- 提出具备跨令牌与跨通道两种选择的 MambaMixer 块,以高效融合信息。
- 展示 ViM2 与 TSM2 在视觉和时间序列预测中的架构。
- 在时间序列中展示具有竞争力的视觉结果和接近最新方法的性能,同时降低计算成本。
提出的方法
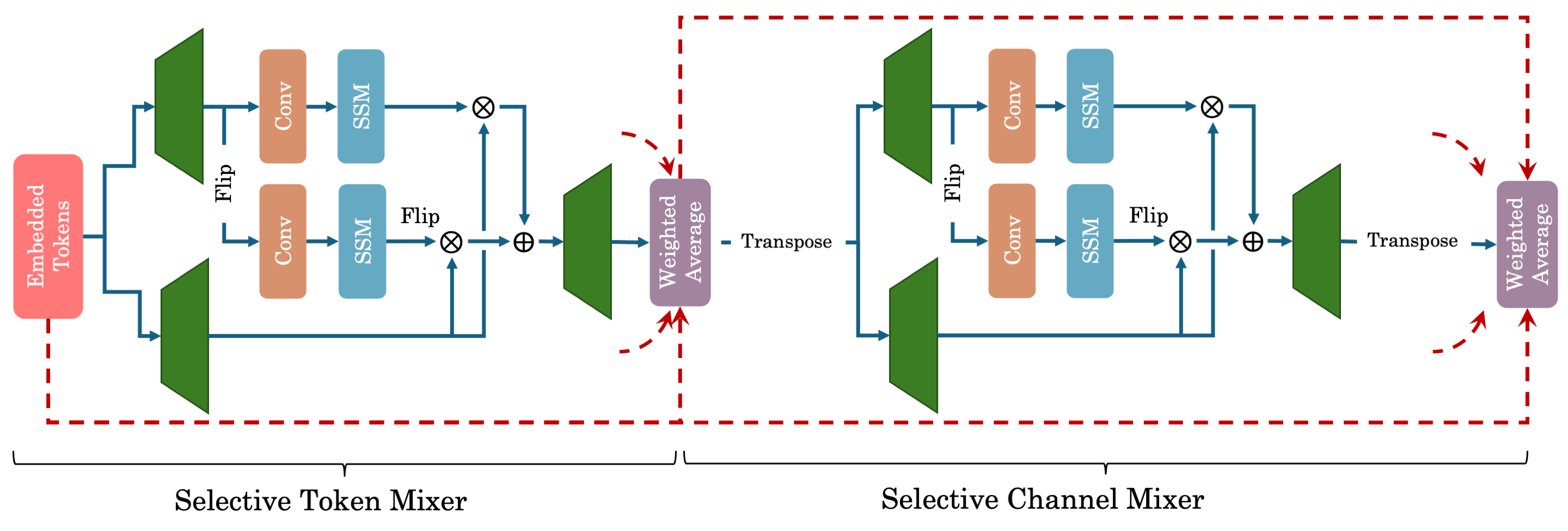
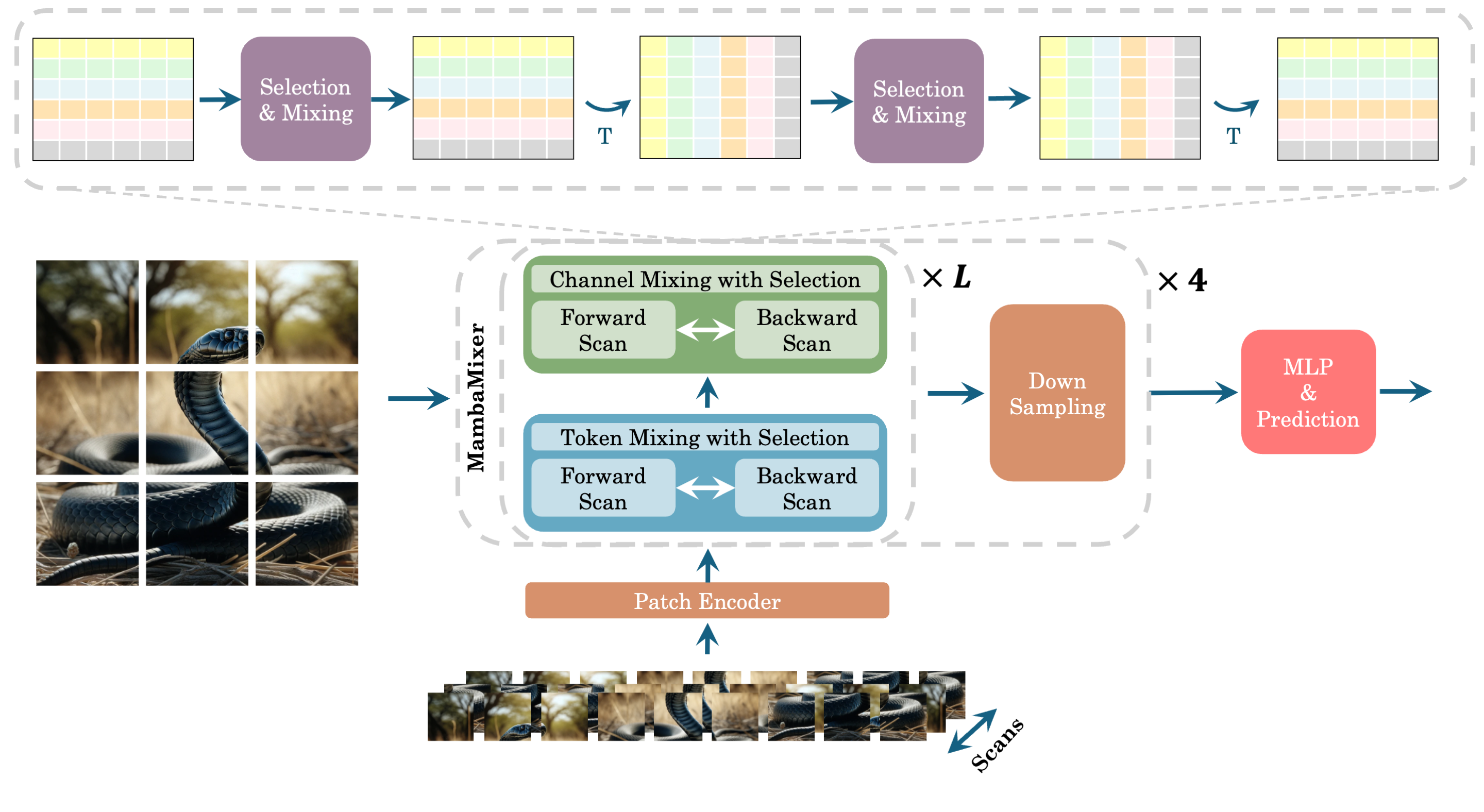
- 基于数据相关的 S6 块,提出 Selective Token Mixer 和 Selective Channel Mixer 模块。
- 扩展到多维数据,具备双向通道混合和用于视觉任务的多扫描方案。
- 引入加权平均机制,以在不同层之间连接早期特征(DenseNet/DenseFormer 风格)。
- 在 ViM2 中应用跨扫描,使用深度卷积和基于 patch 的二维处理用于图像。
- 对 TSM2 使用单向 Selective Token Mixer 和双向 Selective Channel Mixer,结合二维归一化和辅助信息处理。
- 提供架构连接,显示 ViM2 将 MLP-Mixer 和 VMamba 作为特例进行泛化。
实验结果
研究问题
- RQ1双重(令牌和通道)选择性混合是否能比单一维度的选择性 SSM 更好地建模跨令牌和跨通道的依赖?
- RQ2基于 MambaMixer 的 ViM2 与 TSM2 是否能在保持线性时间和空间复杂度的同时实现与最先进视觉和时间序列模型相竞争的结果?
- RQ3在视觉任务(ImageNet、目标检测、语义分割)和时间序列预测方面,与基于 Transformer 的模型和现有 SSM 模型相比,在准确性和效率方面的比较如何?
- RQ4对早期特征的加权平均连接对训练稳定性和大规模性能有何影响?
主要发现
- ViM2 在 ImageNet 上实现了与 ViT、MLP-Mixer、ConvMixer 的竞争性性能,并且优于基于 SSM 的视觉模型。
- TSM2 在多样化时间序列数据集上表现出色,同时与最先进方法相比显著降低计算成本。
- 在两种模态下,跨令牌和跨通道的选择性混合提升信息流和建模能力,超过仅通道或仅令牌的方法。
- 该架构在序列长度和通道数方面保持线性时间和线性空间复杂度,解决了传统注意力的可扩展性问题。
- 模型通过加权平均机制实现对早期特征的直接访问,提升深度 MambaMixer 网络的训练稳定性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。