[论文解读] Many-Shot In-Context Learning
该论文研究大型语言模型如何随 in-context 示例的规模扩展而扩展,提出 Reinforced ICL 与 Unsupervised ICL 以降低对人类演示的依赖,并显示多-shot ICL 能克服预训练偏差并处理非自然语言任务。
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. We also find that inference cost increases linearly in the many-shot regime, and frontier LLMs benefit from many-shot ICL to varying degrees. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
研究动机与目标
- 评估增加上下文中的示例(shots)数量如何影响在多样化任务中的 LLM 性能。
- 开发方法以减少多-shot ICL 对人类生成的推理理由的依赖。
- 分析 ICL 的学习动力学,包括偏差覆盖、非自然语言任务,以及提示顺序效应。
提出的方法
- 系统性地在不同任务上扩大上下文中的示例数量,使用 Gemini 1.5 Pro,最多 8192 个 shots。
- 比较少-shot 与多-shot ICL 在 MT、摘要、规划和代码验证等任务上的表现。
- 通过使用模型生成的推理理由并按答案正确性筛选,引入 Reinforced ICL。
- 通过仅给出题目而不提供推理理由来提示,引入 Unsupervised ICL。
- 分析 ICL 行为,包括偏差克服、高维数值任务,以及 NLL 与 ICL 性能之间的关系。
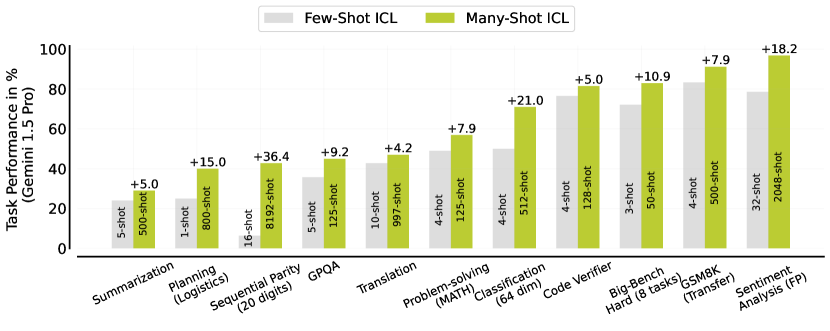
实验结果
研究问题
- RQ1多-shot ICL 的性能如何在广泛任务集上相较于 few-shot ICL 进行扩展?
- RQ2模型生成的推理理由(Reinforced ICL)或仅题目提示(Unsupervised ICL)在多-shot 设置下能否达到或超过人类演示?
- RQ3多-shot ICL 是否能够克服预训练偏差并实现对非自然语言或数值任务的学习?
- RQ4作为 ICL 成功预测指标的 next-token 预测损失有哪些局限?
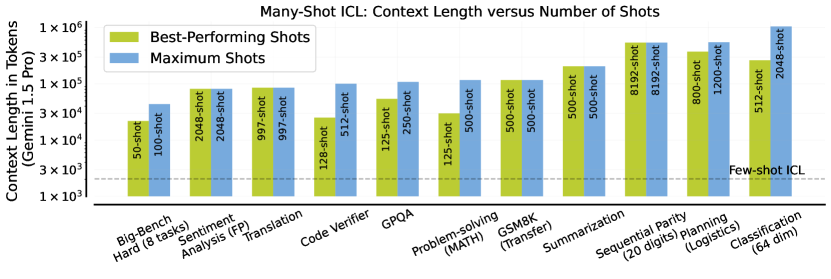
- RQ5多-shot ICL 对示例排序和上下文长度的敏感性如何?
主要发现
- 多-shot ICL 在各任务上带来显著的性能提升,通常当 shots 达到数百到数千个标记时表现达到峰值。
- Reinforced ICL 与 Unsupervised ICL 在许多情境下能超越或匹配人工撰写的推理理由,尤其是在复杂推理任务上。
- 多-shot ICL 能克服预训练偏差并学习高维数值任务,如顺序奇偶性和线性分类等。
- 上下文中的示例顺序对性能有显著影响,即使在多-shot ICL 中也是如此。
- 下一步令牌预测损失可能并不能可靠地预测解决问题和推理任务的下游 ICL 性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。