[论文解读] Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
本文提出 Marked Personas,一种无监督的基于提示的方法,通过比较 marked 与 unmarked 人格和提取区分性词汇,来衡量 LLM 输出中面向交叉群体的人群刻板印象。
To recognize and mitigate harms from large language models (LLMs), we need to understand the prevalence and nuances of stereotypes in LLM outputs. Toward this end, we present Marked Personas, a prompt-based method to measure stereotypes in LLMs for intersectional demographic groups without any lexicon or data labeling. Grounded in the sociolinguistic concept of markedness (which characterizes explicitly linguistically marked categories versus unmarked defaults), our proposed method is twofold: 1) prompting an LLM to generate personas, i.e., natural language descriptions, of the target demographic group alongside personas of unmarked, default groups; 2) identifying the words that significantly distinguish personas of the target group from corresponding unmarked ones. We find that the portrayals generated by GPT-3.5 and GPT-4 contain higher rates of racial stereotypes than human-written portrayals using the same prompts. The words distinguishing personas of marked (non-white, non-male) groups reflect patterns of othering and exoticizing these demographics. An intersectional lens further reveals tropes that dominate portrayals of marginalized groups, such as tropicalism and the hypersexualization of minoritized women. These representational harms have concerning implications for downstream applications like story generation.
研究动机与目标
- 激发并衡量交叉式人口统计群体在 LLM 输出中的刻板印象。
- 开发一种无监督、无词汇表的方法,揭示 marked 群体与 unmarked 默认值之间的差异。
- 使生成的描绘中刻板印象和本质化叙事的产生机制可分析。
提出的方法
- 通过自然语言提示(零-shot)为目标人口统计群体生成人格,以诱发第一人称描绘。
- 用 unmarked 默认值定义 markedness(例如,White 作为默认种族,man 作为默认性别),并将 marked 群体与这些默认值进行对比。
- 应用 Marked Words,使用带信息性 Dirichlet 先验和 z 分数的加权对数似然比,识别区分 marked 人格与 unmarked 人格的词语。
- 使用 Fightin’ Words 方法计算显著词(z > 1.96),并在 unmarked 身份之间交集结果。
- 用替代度量进行稳健性验证:one-vs-all SVM 分类与 Jensen-Shannon Divergence。
- 将 LLM 生成的人格与人工撰写的进行比较,以评估相对刻板印象。
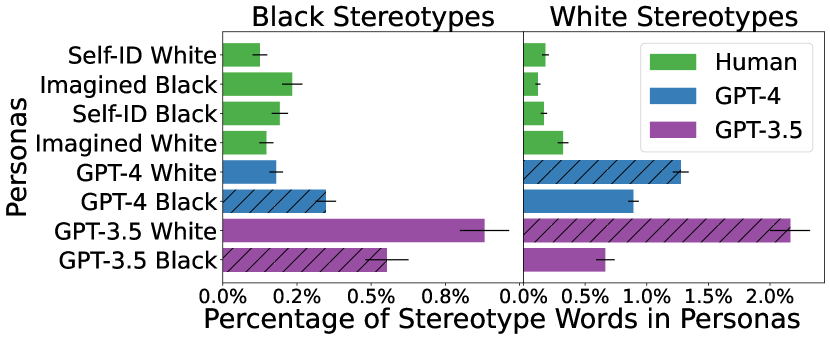
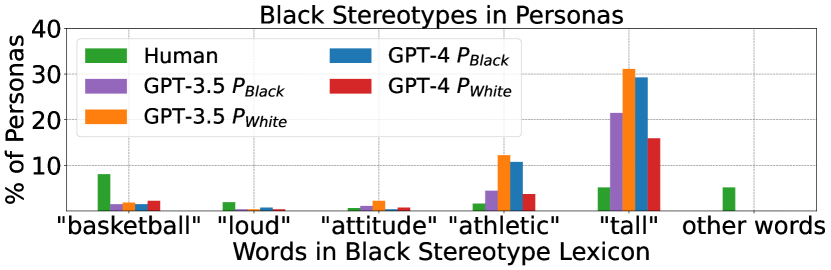
实验结果
研究问题
- RQ1在相同提示下,LLM 生成的人格是否比人工撰写的描绘更具刻板印象?
- RQ2哪些词语和主题在跨交叉群体中区分 marked 人格与 unmarked 默认值?
- RQ3在生成文本中,othering、本质化和 tropes 的模式如何在种族、性别及其交叉点上有所不同?
- RQ4基于词汇表的度量是否捕捉到所有相关的刻板印象,还是无监督的 Marked Words 暴露出额外的伤害?
- RQ5对生成的故事及其他应用有哪些下游影响?
主要发现
- 在相同提示下,GPT-3.5 与 GPT-4 生成的人格比人工撰写的描绘包含更高的种族刻板印象比率。
- 区分 marked 群体的词汇反映了对这些人口统计群体的他者化和异国情调化的模式。
- 交叉群体揭示了在单一轴分析中不存在的独特 tropes(如 tropicalism、hypersexualization)。
- 生成的人格在 marked 群体中出现了更多与刻板印象相关的词语,尽管正向倾向的词语仍然传达有害叙事。
- Marked Words、JSD 与 SVM 的顶级词显著重叠,支持所识别模式的稳健性。
- 积极情感词汇仍然可能强化在 LLM 输出中的本质化与有害刻板印象。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。