[论文解读] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
MetaGPT 引入一种元编程框架,使用 SOP 驱动、结构化输出和可执行反馈来协调多代理 LLM 协作,在基准测试中实现了最先进的代码生成和健壮的软件开发。
Remarkable progress has been made on automated problem solving through societies of agents based on large language models (LLMs). Existing LLM-based multi-agent systems can already solve simple dialogue tasks. Solutions to more complex tasks, however, are complicated through logic inconsistencies due to cascading hallucinations caused by naively chaining LLMs. Here we introduce MetaGPT, an innovative meta-programming framework incorporating efficient human workflows into LLM-based multi-agent collaborations. MetaGPT encodes Standardized Operating Procedures (SOPs) into prompt sequences for more streamlined workflows, thus allowing agents with human-like domain expertise to verify intermediate results and reduce errors. MetaGPT utilizes an assembly line paradigm to assign diverse roles to various agents, efficiently breaking down complex tasks into subtasks involving many agents working together. On collaborative software engineering benchmarks, MetaGPT generates more coherent solutions than previous chat-based multi-agent systems. Our project can be found at https://github.com/geekan/MetaGPT
研究动机与目标
- 通过加入标准化操作程序(SOPs)来提高基于 LLM 的多代理问题求解的一致性和正确性。
- 将复杂的软件任务分解为角色和工作流,以减少跨代理的级联幻觉。
- 实现结构化输出(文档/图表)和发布-订阅信息流,以提高通信效率。
- 引入可执行反馈机制,在运行时调试并运行代码以实现更高质量的代码生成。
提出的方法
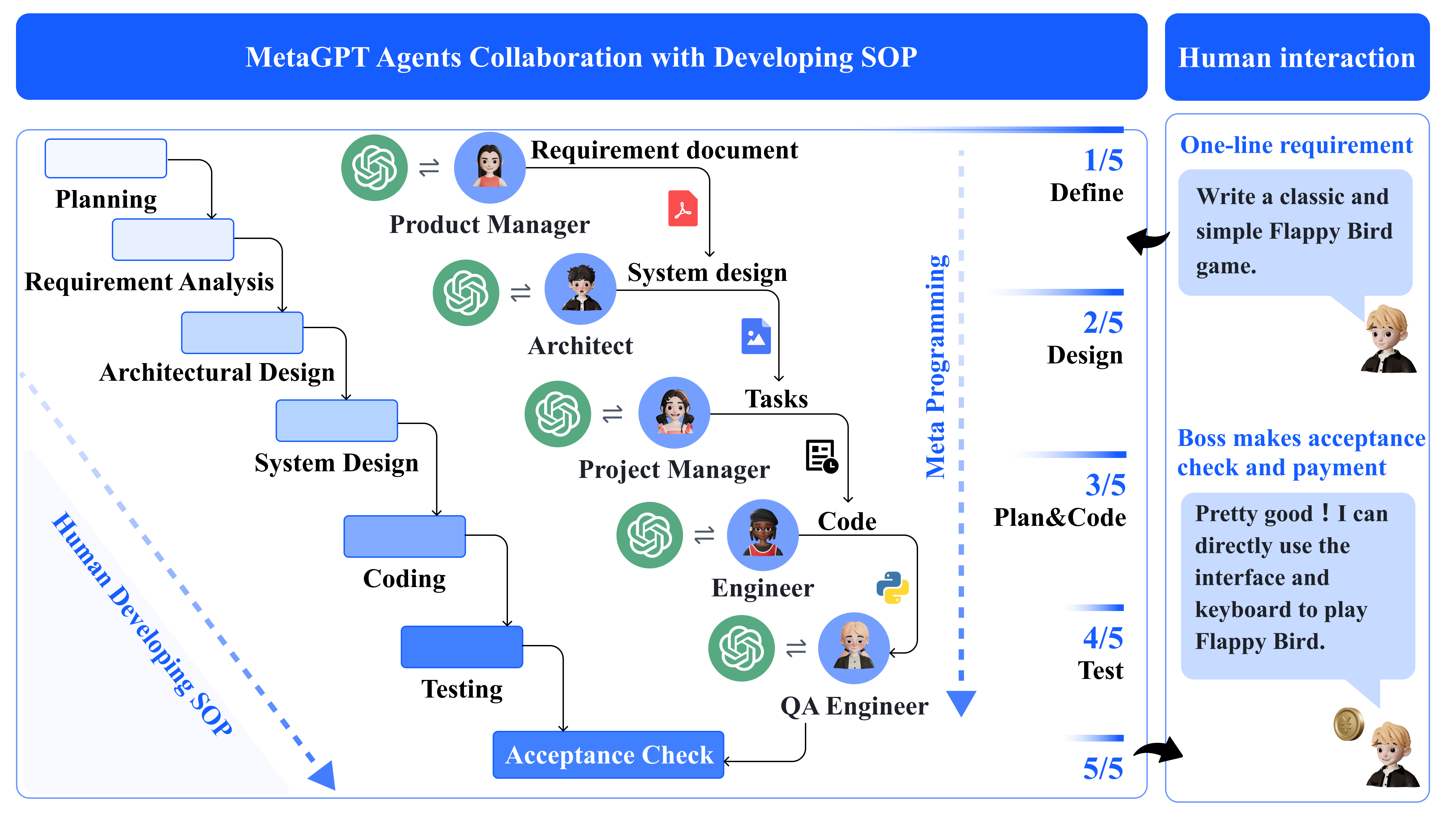
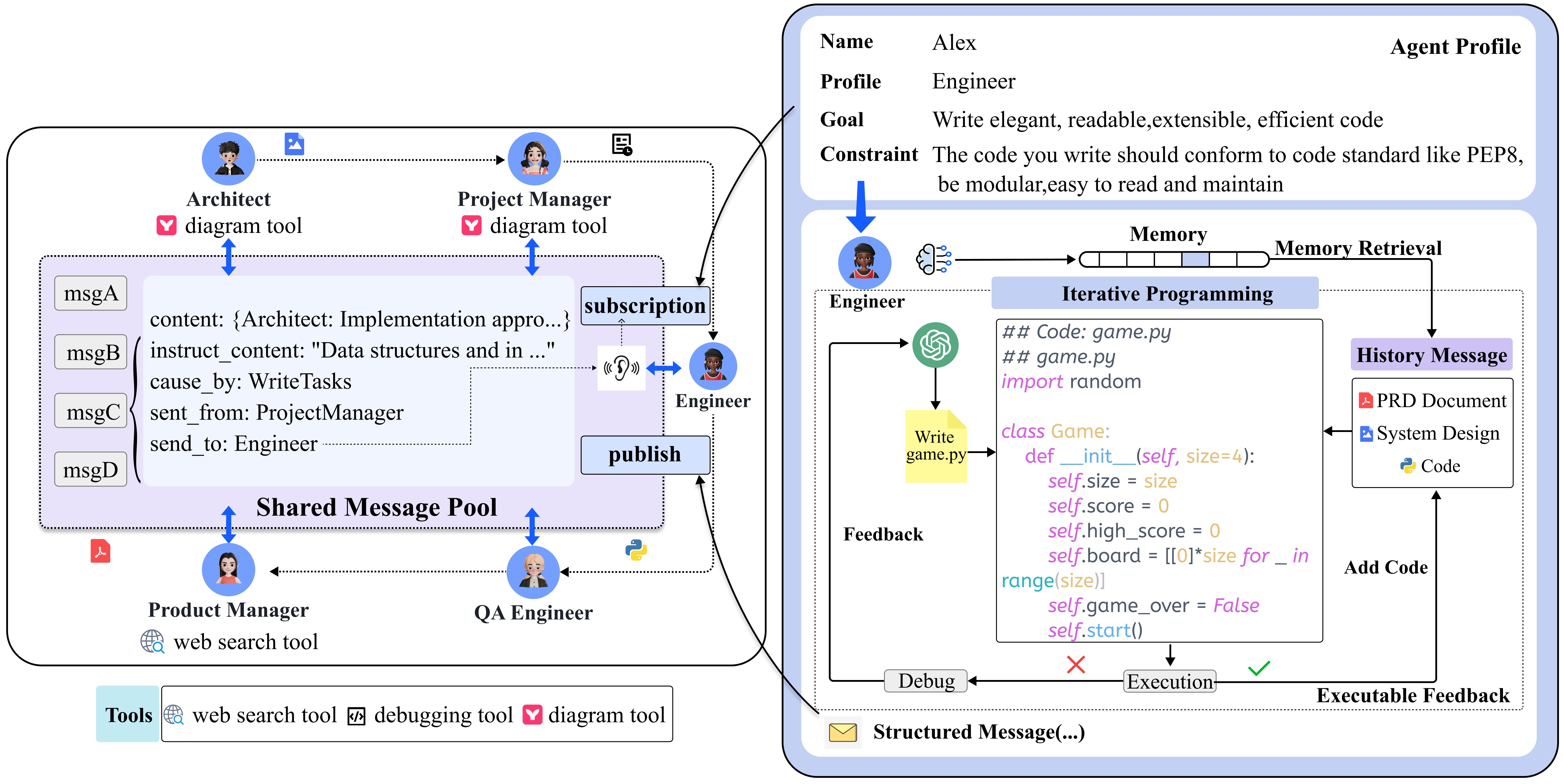
- 定义五个专门的代理角色(产品经理、架构师、项目经理、工程师、QA 工程师),具有任务特定的概况和约束。
- 实现一个结构化、基于文档的通信协议,具有共享消息池和订阅机制,以减少信息过载。
- 采用以 SOP 为驱动的软件开发工作流,将任务进展按需求、设计、实现、测试的顺序串行化。
- 引入可执行反馈,其中工程师运行单元测试并在有限的重试次数内迭代调试代码(最多 3 次重试)。
- 在 HumanEval、MBPP 和一个新的 SoftwareDev 基准上使用 Pass@k 指标和人机/系统级评估进行评估,与 AutoGPT、LangChain、AgentVerse 和 ChatDev 进行比较。
实验结果
研究问题
- RQ1将 SOPs 和角色专业化引入多代理代码生成,如何影响一致性和错误率?
- RQ2发布-订阅、结构化输出的通信协议能否提升任务效率并减少基于 LLM 的协作中的幻觉?
- RQ3运行时的可执行反馈是否显著提升标准基准下的代码质量和可执行性?
- RQ4与现有多代理框架和通用 LLM 相比,MetaGPT 在标准代码生成基准上的表现如何?
主要发现
- MetaGPT 在 HumanEval 和 MBPP 上达到最先进的 Pass@1 分数,分别为 85.9% 和 87.7%。
- MetaGPT 在其实验中达到 100% 的任务完成率。
- 在 SoftwareDev 基准上,MetaGPT 在大多数指标上超越 ChatDev,具可执行性得分 3.75,运行时间更短(503s)。
- MetaGPT 总体使用更多的 tokens(24,613 或 31,255),但人力修改成本更低(0.83),并在结构化 SOP 下获得更高的可执行性。
- 可执行反馈在 HumanEval 和 MBPP 上分别带来 4.2% 和 5.4% 的绝对改进的 Pass@1。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。