[论文解读] MGTBench: Benchmarking Machine-Generated Text Detection
MGTBench 提出一个模块化基准框架,以在强大的 LLMs 面前评估机器生成文本检测方法,比较基于度量的方法和基于模型的方法,评估可迁移性、鲁棒性和文本归因。
Nowadays, powerful large language models (LLMs) such as ChatGPT have demonstrated revolutionary power in a variety of tasks. Consequently, the detection of machine-generated texts (MGTs) is becoming increasingly crucial as LLMs become more advanced and prevalent. These models have the ability to generate human-like language, making it challenging to discern whether a text is authored by a human or a machine. This raises concerns regarding authenticity, accountability, and potential bias. However, existing methods for detecting MGTs are evaluated using different model architectures, datasets, and experimental settings, resulting in a lack of a comprehensive evaluation framework that encompasses various methodologies. Furthermore, it remains unclear how existing detection methods would perform against powerful LLMs. In this paper, we fill this gap by proposing the first benchmark framework for MGT detection against powerful LLMs, named MGTBench. Extensive evaluations on public datasets with curated texts generated by various powerful LLMs such as ChatGPT-turbo and Claude demonstrate the effectiveness of different detection methods. Our ablation study shows that a larger number of words in general leads to better performance and most detection methods can achieve similar performance with much fewer training samples. Moreover, we delve into a more challenging task: text attribution. Our findings indicate that the model-based detection methods still perform well in the text attribution task. To investigate the robustness of different detection methods, we consider three adversarial attacks, namely paraphrasing, random spacing, and adversarial perturbations. We discover that these attacks can significantly diminish detection effectiveness, underscoring the critical need for the development of more robust detection methods.
研究动机与目标
- 为对抗强大的 LLMs 的 MGT 检测与归因创建一个全面、模块化的基准框架。
- 在多个数据集和 LLMs 上评估广泛的基于度量和基于模型的检测方法。
- 分析跨数据集和跨 LLMs 的可迁移性、在对抗扰动下的鲁棒性,以及实际检测效率。
- 提供关于文本长度和训练数据规模如何影响检测性能的见解。
提出的方法
- 具有输入、检测和评估模块的模块化设计。
- 集成十种检测方法(八种基于度量的、五种基于模型的可用集成)。
- 使用公开的 LLMs(例如 ChatGPT-turbo、Claude、ChatGLM、Dolly、GPT4All、StableLM)从人类撰写的文本生成 MGT。
- 评估指标包括准确率、精确率、召回率、F1-score 和 AUC,并进行样本级日志记录。
- 分析文本长度、训练集规模、跨数据集和跨 LLM 的迁移,以及在对抗攻击下的鲁棒性。
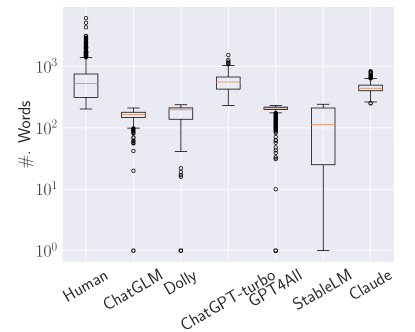
实验结果
研究问题
- RQ1基于度量的和基于模型的 MGT 检测方法在不同数据集和 LLMs 上的表现如何?
- RQ2在一个数据集或一个 LLM 上训练并在另一个数据集或另一个 LLM 上测试时,检测方法的可迁移性特征是什么?
- RQ3检测方法对诸如改述、随机空格和对抗扰动等对抗性攻击有多鲁棒?
- RQ4文本长度如何影响检测性能,以及需要多少训练样本才能实现可靠检测?
- RQ5检测方法能否扩展到文本归因,即识别文本的原始模型?
主要发现
- LM Detector 通常在跨数据集和跨 LLMs 的检测中取得最佳性能。例如,在各任务上实现高 F1-scores(例如 Essay vs ChatGPT-turbo 的 0.993)。
- 基于度量的方法(如 Log-Likelihood、Log-Rank、GLTR、LRR)提供稳健的性能,且在跨 LLM 的可迁移性方面往往优于某些基于模型的方法。
- 较长的文本通常会提升检测性能,200 字通常足以接近最优结果。
- 在文本归因任务中,基于模型的检测器相比基于度量的方法显示出更强的性能。
- 所有方法都对改述、空格与扰动攻击显著脆弱,强调需要更鲁棒的方法。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。