[论文解读] MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
MiniGPT-4 将一个冻结的视觉编码器与一个冻结的先进大语言模型(Vicuna)通过单一投影层对齐,使 GPT-4 类的视觉-语言能力在两阶段训练和精心挑选的高质量数据下可用。
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. However, the technical details behind GPT-4 continue to remain undisclosed. We believe that the enhanced multi-modal generation capabilities of GPT-4 stem from the utilization of sophisticated large language models (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen advanced LLM, Vicuna, using one projection layer. Our work, for the first time, uncovers that properly aligning the visual features with an advanced large language model can possess numerous advanced multi-modal abilities demonstrated by GPT-4, such as detailed image description generation and website creation from hand-drawn drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, teaching users how to cook based on food photos, and so on. In our experiment, we found that the model trained on short image caption pairs could produce unnatural language outputs (e.g., repetition and fragmentation). To address this problem, we curate a detailed image description dataset in the second stage to finetune the model, which consequently improves the model's generation reliability and overall usability. Our code, pre-trained model, and collected dataset are available at https://minigpt-4.github.io/.
研究动机与目标
- 研究将视觉特征与先进的大语言模型对齐是否能够实现 GPT-4 风格的视觉-语言能力。
- 证明仅训练单一投影层就能够有效融合视觉与语言模型。
- 展示对高质量图像描述进行第二阶段微调可以提升生成的可靠性和可用性。
提出的方法
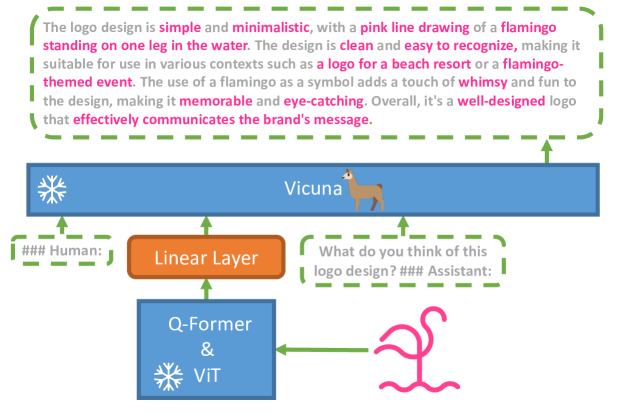
- 使用冻结的 BLIP-2 风格视觉编码器(ViT-G/14 及 Q-Former)和冻结的 Vicuna 作为语言解码器。
- 添加单一线性投影层以将视觉特征对齐到 Vicuna 的嵌入。
- 两阶段训练:(i) 在大规模图像-文本对上进行预训练,组件保持冻结;(ii) 在精心挑选的高质量图像描述数据集上进行微调,并采用设计的对话模板。
- 通过以 Vicuna 风格的对话格式提示模型来生成详细的图像描述,并使用 ChatGPT 进行质量控制的后处理。
- 在高级视觉-语言任务和 COCO 标注上通过定性演示和定量基准进行评估。
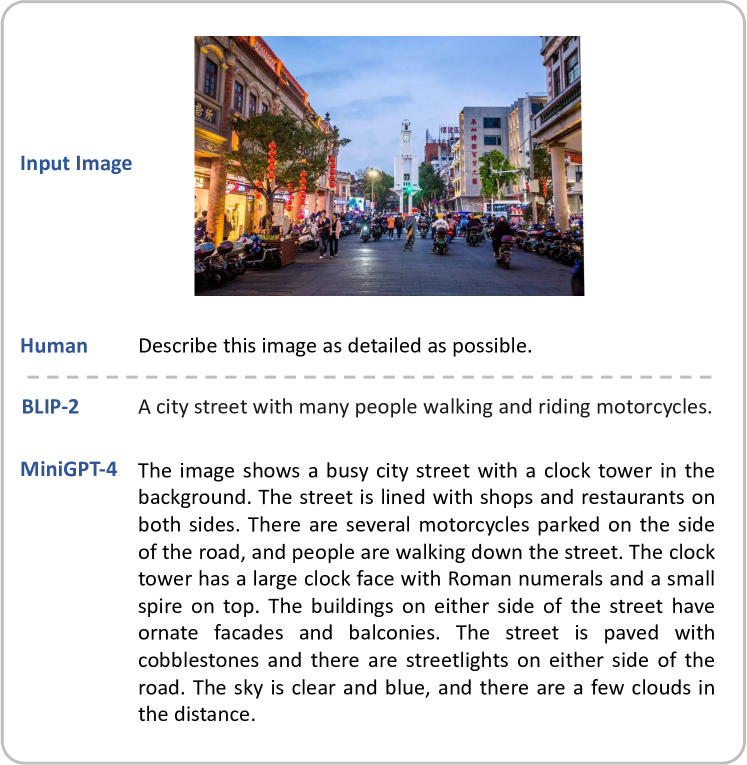
实验结果
研究问题
- RQ1在不更新整个架构的情况下,将视觉特征与先进的 LLM 对齐是否能够实现 GPT-4 级别的视觉-语言能力?
- RQ2在有限数据条件下,单一投影层是否足以有效对齐视觉和语言模型?
- RQ3使用带有详细图像描述的第二阶段微调是否能够提高生成的可靠性和可用性?
- RQ4与基线视觉-语言模型相比,MiniGPT-4 展现了哪些新兴能力?
主要发现
- MiniGPT-4 实现了高级能力,如从手写草稿生成详细的图像描述、对梗图的解读,以及基于草稿创建网站。
- 单一线性投影层足以将冻结的视觉编码器与 Vicuna 对齐,在 4 个 A100 GPU 上约 10 小时的训练即可实现 GPT-4 风格的能力。
- 对经过精心筛选的高质量图像描述数据集进行第二阶段微调可显著减少生成失败(如详细标题和诗歌等)并提升语言自然性。
- 在高级任务上,MiniGPT-4 在用户评判的梗图、食谱、广告和诗歌等回答方面显著优于 BLIP-2(在他们的定性测试中约 65% 的总体成功率)。
- 在 COCO 标注任务中,使用 ChatGPT 评估时,MiniGPT-4 提高了对真实描述的覆盖判断(66.2% 对 27.5% BLIP-2)。
- 消融和架构变体表明,在有限数据条件下,去除 Q-Former 或增加额外层数并不能优于单投影设计。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。