[论文解读] MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback
MINT 是一个基准,用于在多轮设置中评估 LLMs,衡量工具使用带来的增益以及对话式自然语言反馈在多任务中的效果,任务来自现有数据集的再利用。
To solve complex tasks, large language models (LLMs) often require multiple rounds of interactions with the user, sometimes assisted by external tools. However, current evaluation protocols often emphasize benchmark performance with single-turn exchanges, neglecting the nuanced interactions among the user, LLMs, and external tools, while also underestimating the importance of natural language feedback from users. These oversights contribute to discrepancies between research benchmark evaluations and real-world use cases. We introduce MINT, a benchmark that evaluates LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback. To ensure reproducibility, we provide an evaluation framework where LLMs can access tools by executing Python code and receive users' natural language feedback simulated by GPT-4. We repurpose a diverse set of established evaluation datasets focusing on reasoning, coding, and decision-making and carefully curate them into a compact subset for efficient evaluation. Our analysis of 20 open- and closed-source LLMs offers intriguing findings. (a) LLMs generally benefit from tools and language feedback, with performance gains (absolute, same below) of 1-8% for each turn of tool use and 2-17% with natural language feedback. (b) Better single-turn performance does not guarantee better multi-turn performance. (c) Surprisingly, on the LLMs evaluated, supervised instruction-finetuning (SIFT) and reinforcement learning from human feedback (RLHF) generally hurt multi-turn capabilities. We expect MINT can help measure progress and incentivize research in improving LLMs' capabilities in multi-turn interactions, especially for open-source communities where multi-turn human evaluation can be less accessible compared to commercial LLMs with a larger user base.
研究动机与目标
- 评估 LLM 在解决问题时通过多轮工具使用获得的收益。
- 评估自然语言反馈对多轮 LLM 表现的影响。
- 再利用多样的现有数据集,创建一个紧凑且可复现的 MINT 评估集合。
- 在工具增强和反馈启用的多轮设置下,比较开源与封闭源模型。
- 分析多轮评估揭示的工件和失败模式,以指导未来模型的发展。
提出的方法
- 提供一个可重复的评估框架,使 LLM 能通过 Python 解释器执行 Python 代码以使用工具。
- 用 GPT-4 模拟用户的自然语言反馈,以衡量 LLM 利用反馈的能力。
- 从 8 个数据集跨越推理、编码和决策,共计 29,307 个实例中精 curated 出一个紧凑的子集(586 个实例)。
- 在 varying interaction turns (k in {1..5}) 下,评估 4 个封闭源和 16 个开源 LLM,覆盖基础、SIFT、和 RLHF 变体。
- 使用 SR(成功率)作为主要指标,并以回归推导的改进率(Delta_tools)来量化工具增强收益。

实验结果
研究问题
- RQ1在解决任务时,允许多轮工具使用时 LLM 的提升有多大?
- RQ2LLM 在多轮交互中能多大程度上利用模拟的自然语言反馈来提升性能?
- RQ3在多轮、工具启用、反馈增强的评估中,开源模型是否缩小与封闭源模型之间的差距?
- RQ4SIFT 与 RLHF 训练制度对多轮工具使用和反馈利用有何影响?
- RQ5在多轮设置中出现的失败模式有哪些,GPT-4 的反馈是否能与人类反馈一样有效?
主要发现
| 模型 | 大小 | 类型 | k=1 | k=2 | k=3 | k=4 | k=5 | 改善幅度 | R^2 |
|---|---|---|---|---|---|---|---|---|---|
| CodeLLaMA | 7B | Base | 0.3 | 4.1 | 7.2 | 7.2 | 4.3 | +1.1 | 0.38 |
| CodeLLaMA | 7B | SIFT | 0.3 | 7.8 | 10.2 | 9.7 | 8.7 | +1.9 | 0.53 |
| CodeLLaMA | 13B | Base | 0.5 | 13.7 | 17.9 | 19.3 | 18.4 | +4.1 | 0.70 |
| CodeLLaMA | 13B | SIFT | 1.5 | 12.6 | 13.1 | 15.0 | 14.5 | +2.8 | 0.64 |
| CodeLLaMA | 34B | Base | 0.2 | 16.2 | 23.0 | 25.9 | 28.2 | +6.6 | 0.85 |
| CodeLLaMA | 34B | SIFT | 2.6 | 10.1 | 14.7 | 15.4 | 17.1 | +3.4 | 0.86 |
| LLaMA-2 | 7B | Base | 0.2 | 5.6 | 7.3 | 8.9 | 9.7 | +2.2 | 0.87 |
| LLaMA-2 | 7B | RLHF | - | 4.3 | 6.7 | 6.5 | 7.3 | +1.5 | 0.83 |
| LLaMA-2 | 13B | Base | 0.2 | 11.4 | 15.5 | 15.2 | 14.5 | +3.2 | 0.63 |
| LLaMA-2 | 13B | RLHF | 4.1 | 12.5 | 12.5 | 13.3 | 11.9 | +1.7 | 0.47 |
| LLaMA-2 | 70B | Base | 1.9 | 19.4 | 24.6 | 26.4 | 26.4 | +5.6 | 0.73 |
| LLaMA-2 | 70B | RLHF | 4.3 | 14.3 | 15.7 | 16.6 | 17.9 | +3.0 | 0.73 |
| Lemur-v1 | 70B | Base | 1.0 | 17.9 | 23.6 | 25.3 | 26.3 | +5.8 | 0.77 |
| Lemur-v1 | 70B | SIFT | 3.8 | 27.0 | 35.7 | 37.5 | 37.0 | +7.7 | 0.73 |
| Vicuna-v1.5 | 7B | - | 0.0 | 6.7 | 12.3 | 15.4 | 12.6 | +3.4 | 0.77 |
| Vicuna-v1.5 | 13B | - | 0.0 | 2.2 | 4.4 | 6.7 | 8.4 | +2.1 | 1.00 |
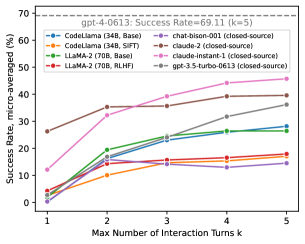
- 所有模型在工具使用和语言反馈方面都受益,每增加一个工具轮次的绝对提升为 1–8%,反馈带来的提升为 2–17%。
- 较强的一轮性能并不在所有情况下保证多轮性能更好。
- 开源模型在多轮性能方面通常落后于最佳的封闭源模型,尽管有些开源模型(如 Lemur-70b-chat-v1)在语言反馈的情况下接近弥补差距。
- SIFT 与 RLHF 训练通常会削弱多轮能力,尽管也存在例外(如 Vicuna-7B、Lemur-70b-chat-v1)。
- GPT-4 模拟的反馈在许多设置中与人类反馈一样有帮助,人工评估者认为 GPT-4 的反馈常常与真实反馈同样有用且更贴近人类。
- 提供反馈的能力与解决任务的能力可能正交,即强的解题者未必总是强的反馈提供者,反之亦然。
- MINT 能检测训练数据中的工件与失败模式(如 ShareGPT 工件),并揭示某些模型在格式化或解析上的问题。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。