[论文解读] MixFormerV2: Efficient Fully Transformer Tracking
MixFormerV2 引入一个完全的 transformer 跟踪框架,使用预测令牌和基于蒸馏的模型缩减,在 GPU 和 CPU 上以实时速度实现高精度。
Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.
研究动机与目标
- 以适用于实时部署的 transformer 基方法来推动高效的可视视觉对象跟踪。
- 提出一个无需密集卷积或复杂分数头的完全 transformer 跟踪框架。
- 引入预测令牌以捕获目标-模板和搜索区域的相关性。
- 开发基于蒸馏的模型缩减(从密集到稀疏,及从深到浅)以提升效率。
- 在标准跟踪基准上展示强烈的精度-速度权衡。
提出的方法
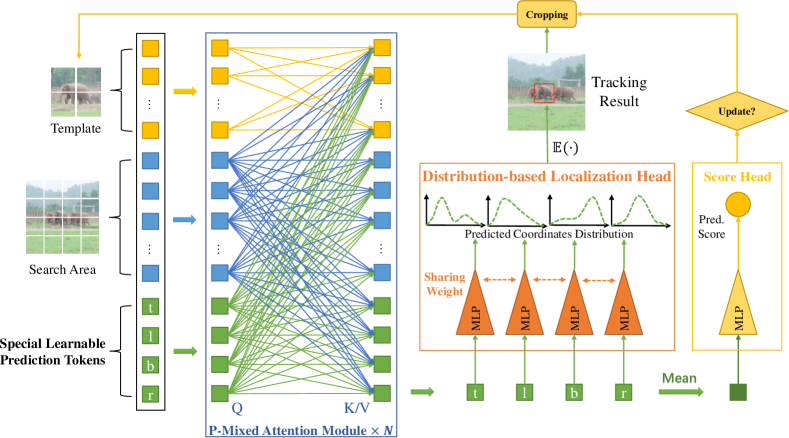
- 使用四个可学习的预测令牌,与模板令牌和搜索令牌拼接,形成混合令牌序列。
- 应用包含预测令牌的混合注意力(P-MAM)来编码目标-搜索相关性。
- 通过在预测令牌上使用共享的 MLP 头,直接回归四个框坐标(基于分布的回归)。
- 通过简单的 MLP 头对预测令牌求平均来预测目标质量分数。
- 执行从 dense-head MixViT 到 MixFormerV2 的从密集到稀疏的蒸馏,以迁移定位知识。
- 应用带有渐进深度剪枝和中间教师的深到浅蒸馏,以在保留迁移能力的同时剪枝骨干网络。
- 包含 MLP 维度降低(MLP-r)以降低 CPU/GPU 延迟。
- 通过蒸馏损失进行训练,结合框回归、CIoU、对数 logits 蒸馏和特征模仿。
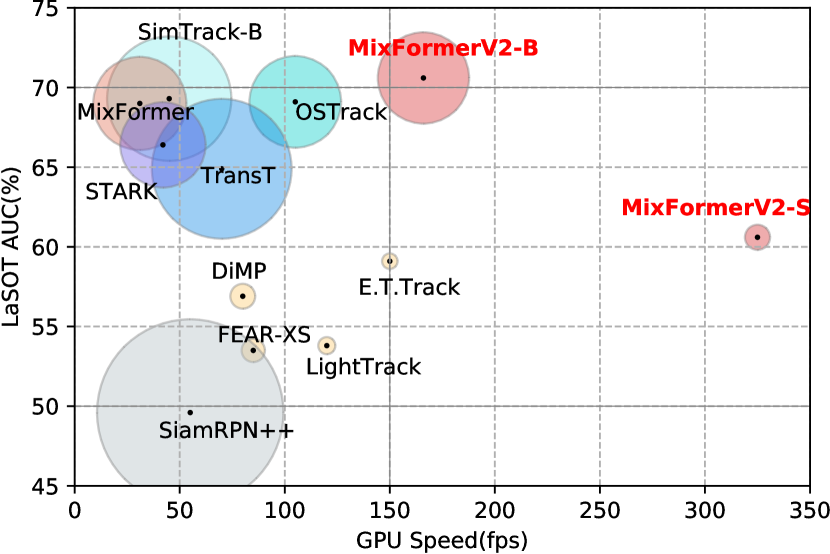
实验结果
研究问题
- RQ1一个完全基于 transformer 的跟踪模型在没有密集卷积的情况下,是否能够实现具有竞争力的准确性和更高的效率?
- RQ2预测令牌和基于令牌的回归如何影响定位准确性和推理速度?
- RQ3知识蒸馏(密集到稀疏,以及深到浅)是否可以提升更轻量的 MixFormerV2 的性能?
- RQ4中间教师和 MLP 降维对 CPU 实时性能有什么影响?
主要发现
- MixFormerV2-B 在 LaSOT 上取得 70.6% 的 AUC,GPU 上达到 165 FPS。
- MixFormerV2-S 在保持 LaSOT 竞争性性能的同时实现 CPU 实时速度。
- 基于预测令牌的分布回归,使用四个令牌,优于直接单令牌回归,并在速度-精度权衡方面与密集角点头同等或更优。
- 来自 MixViT 的密集到稀疏蒸馏使 MixFormerV2 的准确度提升约 1.4–2.2% AUC,具体取决于教师模型。
- 带有渐进深度剪枝的深到浅蒸馏在降低骨干深度(如从 12 层到 8 层再到 4 层工作流)的同时保留了大部分准确性。
- 中间教师在蒸馏中有助于非常浅的模型(如 4 层),带来额外收益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。