[论文解读] MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition
提出 MixSpeech,一种跨模态自学习框架,利用混合的音视频语音来正则化视觉语音翻译和唇读,在 AVMuST-TED 和 LRS/LRS2/CMLR 数据集上取得了最先进的结果。
Multi-media communications facilitate global interaction among people. However, despite researchers exploring cross-lingual translation techniques such as machine translation and audio speech translation to overcome language barriers, there is still a shortage of cross-lingual studies on visual speech. This lack of research is mainly due to the absence of datasets containing visual speech and translated text pairs. In this paper, we present extbf{AVMuST-TED}, the first dataset for extbf{A}udio- extbf{V}isual extbf{Mu}ltilingual extbf{S}peech extbf{T}ranslation, derived from extbf{TED} talks. Nonetheless, visual speech is not as distinguishable as audio speech, making it difficult to develop a mapping from source speech phonemes to the target language text. To address this issue, we propose MixSpeech, a cross-modality self-learning framework that utilizes audio speech to regularize the training of visual speech tasks. To further minimize the cross-modality gap and its impact on knowledge transfer, we suggest adopting mixed speech, which is created by interpolating audio and visual streams, along with a curriculum learning strategy to adjust the mixing ratio as needed. MixSpeech enhances speech translation in noisy environments, improving BLEU scores for four languages on AVMuST-TED by +1.4 to +4.2. Moreover, it achieves state-of-the-art performance in lip reading on CMLR (11.1\%), LRS2 (25.5\%), and LRS3 (28.0\%).
研究动机与目标
- 由于缺乏带翻译的视觉语音,推动跨语言视觉语音研究。
- 引入 AVMuST-TED,首个面向四种语言的音视频多语言语音翻译数据集。
- 开发一个跨模态自学习框架,利用高辨别的音频语音对视觉语音进行正则化。
- 通过混合语音桥接模态差距,提升知识转移和在嘈杂环境中的鲁棒性。
- 在多数据集上展示最先进的唇部翻译和唇读性能。
- 提供关于跨语言视觉语音翻译的见解及潜在应用。
提出的方法
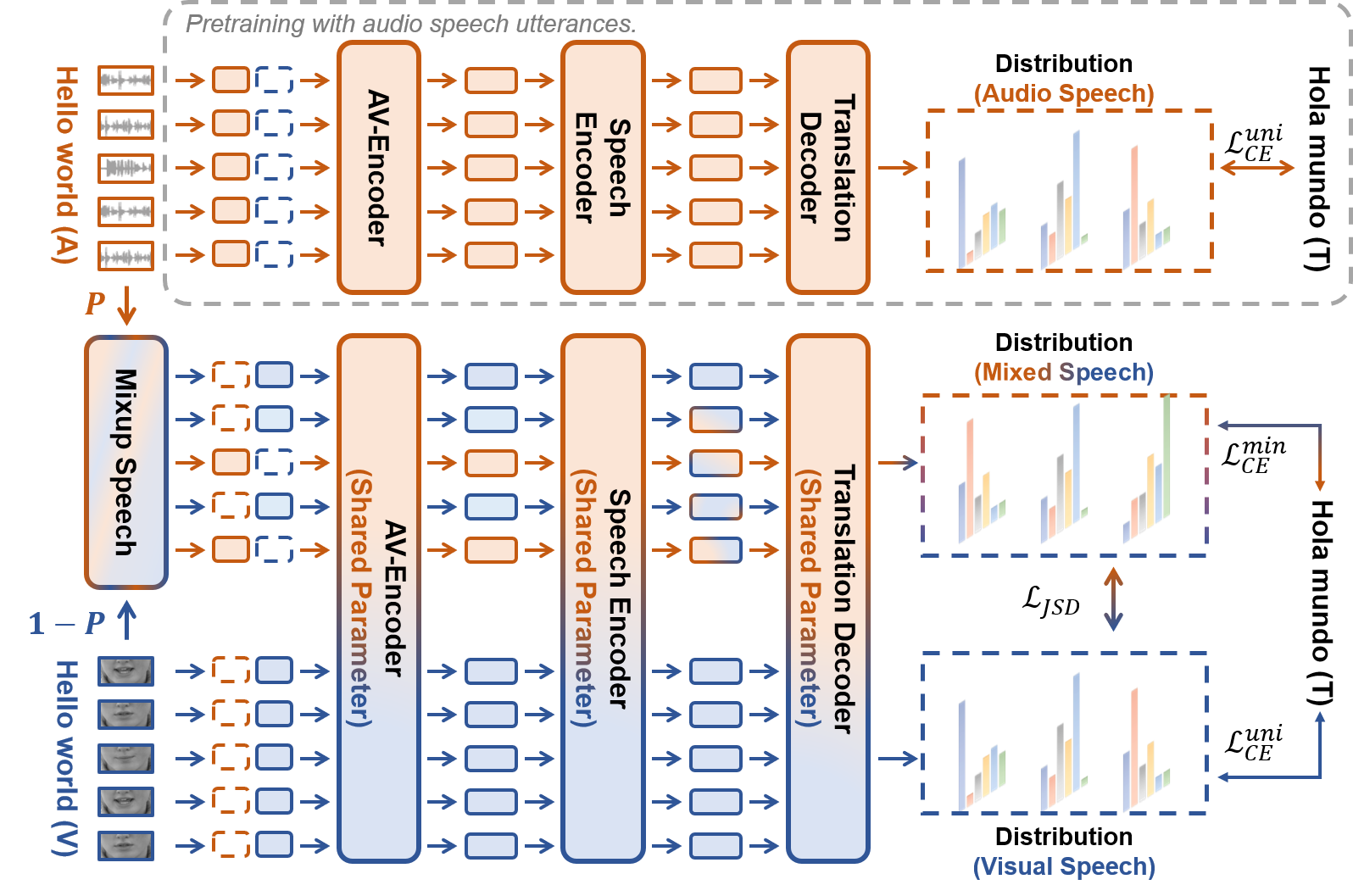
- 在高辨别音频语音上预训练一个翻译解码器,以学习源音素到目标语言文本的跨语言映射。
- 通过跨模态自学习将视觉语音与音频语音对齐,以将音频派生的映射迁移到视觉语音。
- 通过在帧级对音频与视觉语音进行插值,合成混合语音以弥合模态差距(MixSpeech)。
- 在训练中基于预测不确定性使用课程学习来调整混合比。
- 用 Jensen-Shannon 散度对视觉与混合语音翻译进行正则化,以在保持音视知识的同时对齐输出分布,并通过混合目标损失实现。
实验结果
研究问题
- RQ1音频语音的预训练是否可以提升视觉语音翻译并减少跨模态转移差距?
- RQ2通过插值音频与视觉流(混合语音)是否进一步缩小模态差距并提升视觉语音翻译性能?
- RQ3基于课程的混合策略是否能够在训练过程中自适应地优化跨模态知识转移?
- RQ4在不同资源条件下,MixSpeech 在 AVMuST-TED 唇译和标准唇读基准(LRS2、LRS3、CMLR)上的表现如何?
主要发现
| Method | BLEU En-Es | BLEU En-Fr | BLEU En-It | BLEU En-Pt |
|---|---|---|---|---|
| Cascaded V | 12.7 | 11.3 | 11.5 | 13.2 |
| AV-Hubert V | 14.2 | 12.6 | 12.9 | 14.8 |
| Cascaded A(+Noise) | 16.0 | 12.9 | 12.6 | 15.5 |
| AV-Hubert A(+Noise) | 17.6 | 14.5 | 14.1 | 17.1 |
| MixSpeech(V) | 18.5 | 15.1 | 14.3 | 17.2 |
- 与基线相比,MixSpeech 在 AVMuST-TED 的四种语言上将视觉语音翻译的 BLEU 提升了 +1.4 至 +4.2。
- 端到端的 MixSpeech 在 AVMuST-TED 上实现了最先进的唇部翻译,在 LRS2(25.5%)、LRS3(28.0%)和 CMLR(11.1%)的唇读也达到了最先进水平。
- MixSpeech 通过使用混合语音来弥合跨模态差距,当混合比配置得当时(如 En-Es)有显著增益。
- 基于课程学习的混合比在训练中自适应,进一步提升翻译性能。
- 在嘈杂音频条件下,MixSpeech 保持鲁棒性,并在视觉语音翻译上优于仅音频的基线。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。