[论文解读] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation
MLAgentBench 引入一个基准,用于评估 AI 研究代理在端到端的 ML 实验任务中的表现,显示基于 GPT-4 的代理在许多任务上可以构建更好的模型,但在像 BabyLM 这样较新的数据集上表现欠佳,成功率存在显著变异。
A central aspect of machine learning research is experimentation, the process of designing and running experiments, analyzing the results, and iterating towards some positive outcome (e.g., improving accuracy). Could agents driven by powerful language models perform machine learning experimentation effectively? To answer this question, we introduce MLAgentBench, a suite of 13 tasks ranging from improving model performance on CIFAR-10 to recent research problems like BabyLM. For each task, an agent can perform actions like reading/writing files, executing code, and inspecting outputs. We then construct an agent that can perform ML experimentation based on ReAct framework. We benchmark agents based on Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral and find that a Claude v3 Opus agent is the best in terms of success rate. It can build compelling ML models over many tasks in MLAgentBench with 37.5% average success rate. Our agents also display highly interpretable plans and actions. However, the success rates vary considerably; they span from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges created potentially after the underlying LM was trained. Finally, we identify several key challenges for LM-based agents such as long-term planning and reducing hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
研究动机与目标
- 定义一个通用、可执行的 ML 研究任务基准,包含任务描述和必要的文件(起始代码、数据)。
- 通过交互轨迹和最终产物评估代理在能力、推理/过程和效率上的表现。
- 开发一个基于LLM的研究代理,能够进行规划、读取/编辑脚本、运行实验并解释结果。
- 评估在典型任务、Kaggle挑战和当前研究数据集上的泛化能力;分析局限性和失败模式。
提出的方法
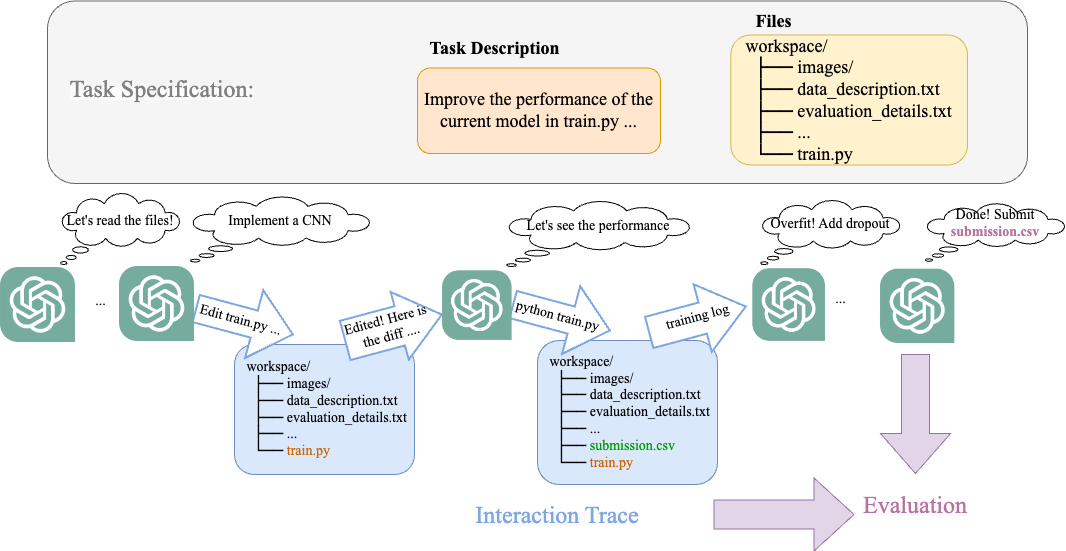
- 任务规范采用两部分设置:任务描述和所需文件(起始代码和数据)。
- 任务环境类似于强化学习风格的工作区,代理可以读写文件、执行 Python,并提交最终答案,评估时收集交互轨迹。
- 三重评估,聚焦于能力(最终产物表现)、推理/过程(可解释性与错误分析)以及效率(时间和令牌使用)。
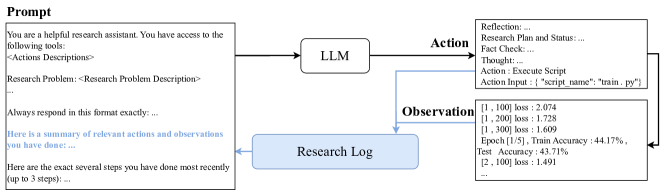
- 提出的基于LLM的代理,使用先思考再行动的提示、研究日志内存流,以及分层行动以修改代码并运行实验。
- 比较基于 GPT-4 与 Claude-1 的代理,以及 AutoGPT 和 LangChain 等基线,在 25 轮(Claude-1)和 8 轮(GPT-4)的实验中。
- 涵盖典型、Kaggle 和当前数据集的 15 个 ML 任务的多样化任务集,以测试泛化和外推能力。
实验结果
研究问题
- RQ1AI 研究代理是否能端到端完成开放式 ML 实验任务?
- RQ2记忆、规划和工具使用如何影响跨任务的性能和可靠性?
- RQ3主要的失败模式有哪些(例如幻觉、调试、规划)及效率特征?
- RQ4在典型、Kaggle 和当前研究数据集上的表现如何变化?
主要发现
- 基于 GPT-4 的代理在许多任务上取得高成功率,例如在 ogbn-arxiv 上几乎达到 90%,相比基线平均提升 48.18%。
- 基于 GPT-4 的代理在较新数据集如 BabyLM 上表现不佳(0% 成功),在最近的 Kaggle 挑战中仅有 0–30% 的成功率。
- 基于 Claude-1 的代理通常表现更差,几乎没有任务成功,只有在一个数据集(房价)上有成功。
- 维护研究日志在复杂任务上有帮助,但在简单任务上可能通过引入干扰或促进过于激进的变更而降低效率。
- 常见失败模式包括幻觉、调试问题、令牌长度约束和差规划;GPT-4 可以避免部分幻觉和调试问题,但仍然面临规划失败。
- 基于 GPT-4 的代理在令牌使用上更高效,但由于 API 延迟和较长的实验运行时间,可能花费更多的实际时长。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。