QUICK REVIEW
[论文解读] MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Xiangxiang Chu, Limeng Qiao|arXiv (Cornell University)|Feb 6, 2024
Multimodal Machine Learning Applications被引用 10
一句话总结
MobileVLM V2 通过扩展数据、改进训练策略并引入轻量级投影器,实现面向移动的视觉—语言模型更快更强,并在较低延迟下达到比许多更大模型更好的最先进准确度。
ABSTRACT
We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
研究动机与目标
- 使 VLM 在资源受限设备(移动/边缘)上更具实用性为目标。
- 研究数据扩展和训练策略以缩小小型 VLM 与大型 VLM 之间的差距。
- 设计轻量级投影机制以高效对齐视觉与语言特征。
- 展示开放且高质量的数据和端到端训练如何提升小型 VLM 的性能。
- 在标准基准上展示 Pareto 最优的准确性-延迟权衡。
提出的方法
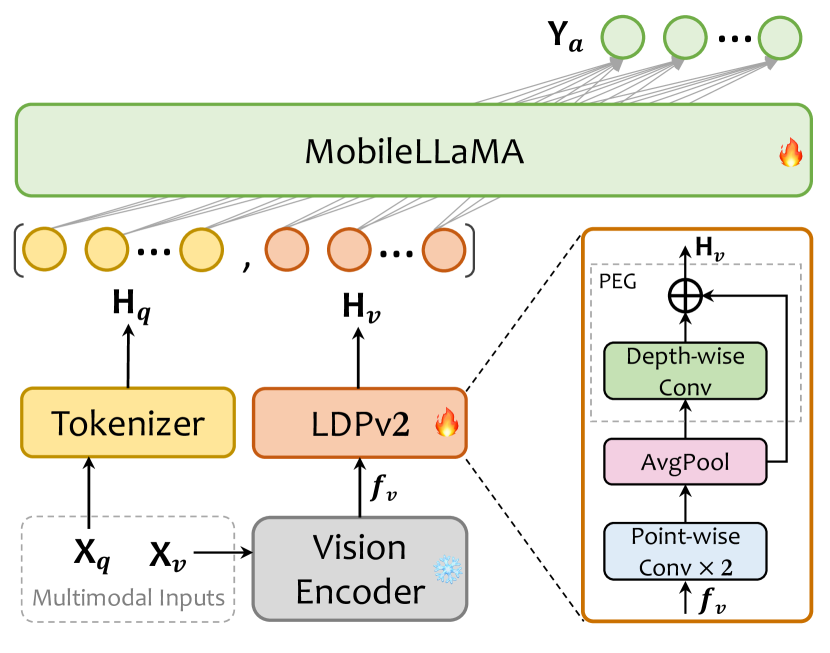
- 将 CLIP ViT-L/14 作为 vision 编码器,输入分辨率为 336x336。
- 采用 MobileLLaMA(1.4B/2.7B)作为语言模型,以实现开放、有效的推理。
- 引入轻量级下采样投影器(LDPv2),通过池化和简单卷积并结合位置增强来减少图像 token。
- 分两步训练:预训练(图像-文本对齐,搭配完整投影器+LLM)与多任务训练(视觉-语言任务)。
- 在 ShareGPT4V-PT(1.2M 图像-文本对)上进行预训练,并在来自多样 VLM 数据集的 240 万样本上进行多任务训练。
- 在保持视觉编码器冻结的同时微调所有投影器和 LLM 参数,以提升效率和数据利用率。
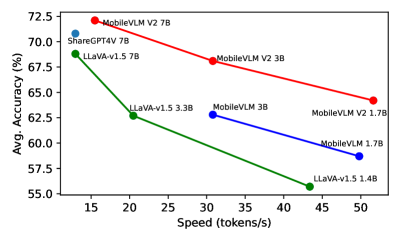
实验结果
研究问题
- RQ1数据缩放与高质量多模态数据集是否能提升小型 VLM 的性能以接近大型模型?
- RQ2一个轻量级、下采样的视觉投影是否能在对移动友好型 LLMs 上有效桥接视觉与语言?
- RQ3哪种训练方案(预训练 vs. 多任务)能最好地利用高质量数据来提升小型 VLM 的效果?
- RQ4与现有最先进的 VLM 相比,MobileVLM V2 在准确性和延迟方面在标准基准上表现如何?
主要发现
- MobileVLM V2 1.7B 在标准基准上达到与更大 VLM 相当或更好的性能。
- 3B 的 MobileVLM V2 在基准上平均表现优于许多 7B 规模以上的 VLM。
- MobileVLM V2 相比某些基线实现约 75% 的更快推理,同时达到更高的平均准确率。
- 7B 的 MobileVLM V2 在桌面/移动端相似测试设置下在准确度和速度上超越若干大型 VLM。
- 高度数据高效的端到端训练方案结合轻量级投影器形成强劲的准确性-延迟帕累托前沿。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。