[论文解读] Model evaluation for extreme risks
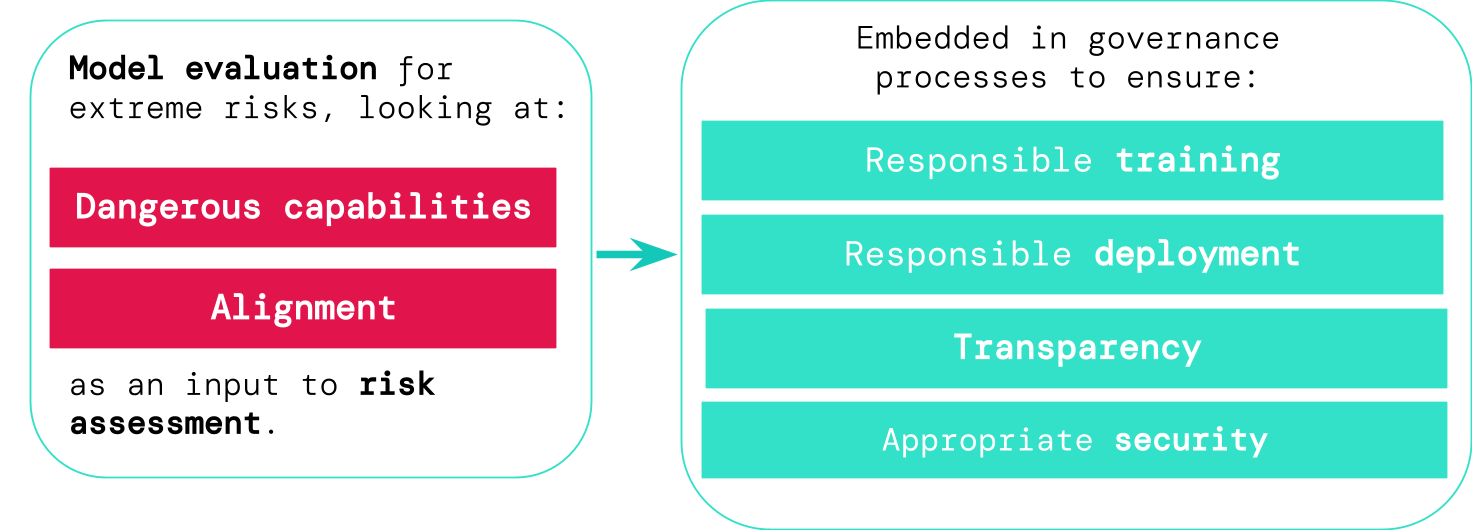
本文主张一种两大支柱的评估框架——危险能力与对齐性——以评估通用模型的极端风险,并概述如何在治理、培训、部署、透明度与安全性中嵌入这些评估。
Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
研究动机与目标
- 推动关注前沿/通用AI模型的极端风险,并界定危险能力和不对齐风险的范围。
- 提出一个以治理为导向的框架,将模型评估嵌入到培训、部署、透明度和安全流程中。
- 概述早期工作、设计标准和局限性,以指导未来的极端风险评估发展。
- 建议开发者和政策制定者如何利用评估来管理培训、部署与风险缓解。
提出的方法
- 定义两大核心评估目标:(一)检测模型可能具备的危险能力;(二)评估其将这些能力以有害方式付诸应用的倾向性(对齐)。
- 描述一个端到端的治理工作流程,在该流程中内部评估、外部研究访问和独立审计为培训风险评估、部署风险评估和事件报告提供信息。
- 提出极端风险评估的设计标准,包括全面性、自动化、行为与机制分析、故障排查、潜在能力暴露、生命周期覆盖和可解释性。
- 倡导负责任的培训和部署实践:基于评估结果暂停或调整培训/部署,逐步部署并进行部署后监测。
- 强调透明性机制(事件报告、部署前风险评估、科学报告、教育性演示)与安全实践(红队演练、隔离、快速响应、系统完整性)。
- 参考早期倡议(ARC Evals、OpenAI、Google DeepMind)作为危险能力与对齐评估在实践中的示例。
实验结果
研究问题
- RQ1前沿通用模型可能具备哪些危险能力,如何可靠地检测它们?
- RQ2如何在不同环境中评估模型错用其能力(对齐性)的倾向性?
- RQ3应如何将极端风险评估整合到培训、部署和治理中,以降低极端风险暴露?
- RQ4关于极端风险的模型评估存在哪些局限性与潜在危害,以及如何降低?
主要发现
- 提出一个两类评估框架:危险能力与对齐性,用以评估极端风险。
- 概述一个治理工作流程,将评估嵌入到风险评估、培训、部署和安全决策中。
- 识别了一组非穷尽性的危险能力,并讨论它们的组合如何增加风险。
- 描述评估组合的理想特质,包括广度、自动化、故障排查能力以及模型生命周期的考虑。
- 强调由于不可预期的行为和模型更新,部署后持续评估和监控。
- 承认评估的局限性和潜在危害,如未知的威胁模型、涌现性和信息泄露风险。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。