[论文解读] Multi-Source Conformal Inference Under Distribution Shift
开发一个在缺失结果和分布偏移情况下,针对目标人群使用多源潜在有偏数据源的分布无关预测区间,采用数据自适应加权和隐私保护的联邦更新。
Recent years have experienced increasing utilization of complex machine learning models across multiple sources of data to inform more generalizable decision-making. However, distribution shifts across data sources and privacy concerns related to sharing individual-level data, coupled with a lack of uncertainty quantification from machine learning predictions, make it challenging to achieve valid inferences in multi-source environments. In this paper, we consider the problem of obtaining distribution-free prediction intervals for a target population, leveraging multiple potentially biased data sources. We derive the efficient influence functions for the quantiles of unobserved outcomes in the target and source populations, and show that one can incorporate machine learning prediction algorithms in the estimation of nuisance functions while still achieving parametric rates of convergence to nominal coverage probabilities. Moreover, when conditional outcome invariance is violated, we propose a data-adaptive strategy to upweight informative data sources for efficiency gain and downweight non-informative data sources for bias reduction. We highlight the robustness and efficiency of our proposals for a variety of conformal scores and data-generating mechanisms via extensive synthetic experiments. Hospital length of stay prediction intervals for pediatric patients undergoing a high-risk cardiac surgical procedure between 2016-2022 in the U.S. illustrate the utility of our methodology.
研究动机与目标
- 使用多个异构数据源为目标站点的缺失结果提供有效的预测区间。
- 当条件结果分布在各站点不同步时,利用源站点的信息。
- 在不共享个体层面数据的前提下实现名义覆盖率。
- 在保持效率的同时,将机器学习预测用于 nuisance 成分。
提出的方法
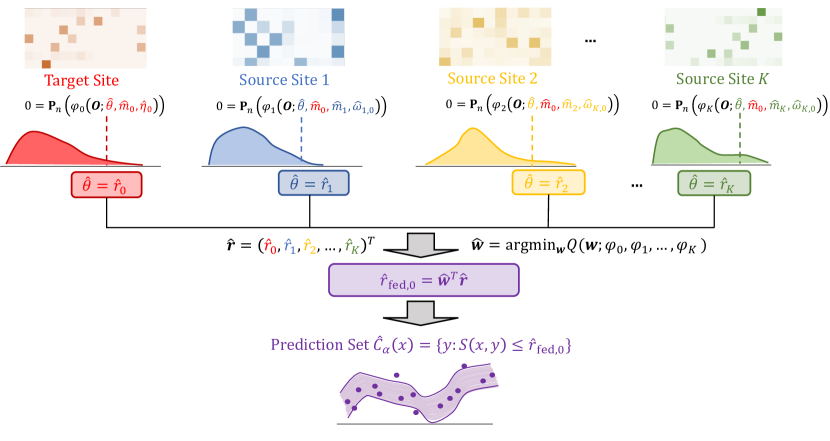
- 为实现1-α边际覆盖,定义 conformal score S(X,Y) 和目标分位数 r0。
- 在通常的条件结果分布(CCOD)和缺失在随机假设下推导 r0 的高效影响函数。
- 提出交叉拟合和基于 Super Learner 的 nuisance 估计以实现参数化类似的收敛速率。
- 引入数据自适应联邦加权以在 CCOD 被违反时结合站点特定分位数 r_k。
- 提供一种保护隐私的程序,以最小的数据共享来计算密度比和站点特定量。
- 给出一个 oracle 覆盖率结果,显示在指定条件下 weighted 聚合可以保持名义覆盖。
实验结果
研究问题
- RQ1是否可以使用来自多个异构站点、存在缺失结果的数据构建目标人群的有效的分布无关预测区间?
- RQ2当条件结果分布在各站点不一致时,如何整合来自源站点的信息?
- RQ3在多站点一致性推断中,能够处理协变量分布偏移和异质性的有效影响函数和估计策略有哪些?
- RQ4数据自适应的联邦相比仅针对目标或合并样本的方法,对覆盖率和区间宽度有何影响?
主要发现
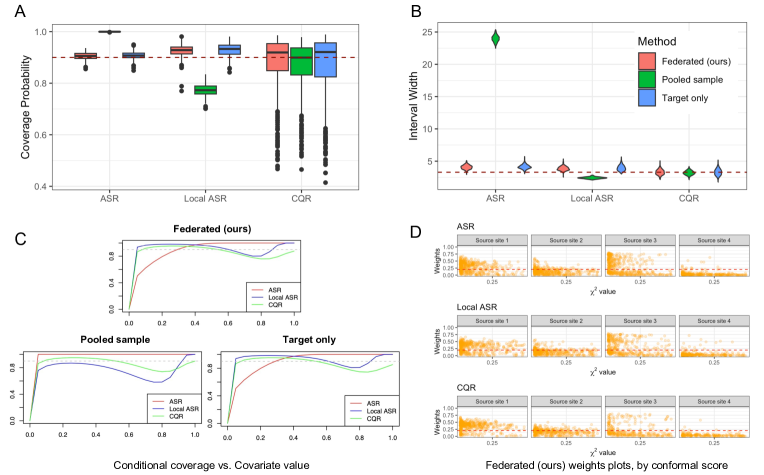
- 所提方法在 MAR 和 CCOD 假设下实现名义覆盖率的有效预测区间,同时利用来自多个站点的信息。
- 在 CCOD 下的有效影响函数使跨站点数据聚合成为可能,以改进对目标站点分位数 r0 的估计。
- 一种数据自适应的联合机制在 CCOD 被违反时为各站点分配权重,从而减少非信息源带来的偏差,提升效率。
- 交叉拟合和 SuperLearner 允许灵活的 nuisance 估计而不牺牲覆盖保证。
- 实证结果显示在多种模拟情景下,联邦区间相比仅目标和合并样本方法更紧凑且具有竞争性的准确性。
- 关于先天性心脏缺陷医院出院天数的应用展示了区间相对于目标仅方法的实际收窄。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。