[论文解读] Multi-Stage Learning for Grasp-Constrained Object Manipulation with a Simulated Panda Robot
本文介绍 robosuite,这是一个基于 MuJoCo 的模块化仿真框架与机器人学习基准,提供标准化任务、过程化环境生成和多模态感知,以支持可重复的研究。
This repository contains code and experiment assets for RAES (Reward-Aligned Expert Sequencing) and RSTB (Reward-Saturated Temporal Branching)—two lightweight reinforcement learning (RL) frameworks for long-horizon robotic manipulation without demonstrations, learned high-level controllers, or heavy task engineering. We study the robosuite [1] Stack benchmark (reach → grasp → lift/align → stack) and show that coupling continuous shaping with discrete endpoints into reward pairs produces a smoother, more learnable landscape. RAES aligns modular experts with these reward pairs (reach–grasp; lift/align–stack) and executes them sequentially. Across 10M timesteps and 5 seeds, RAES achieves the strongest performance under paired rewards, reaching 223.27 ± 28.68 mean return and 19.30% ± 2.55% success—surpassing PPO and curriculum baselines—while remaining fully RL-based (no demonstrations or hand-coded subtasks). Note: RAES and RASE (Reward Aligned Sequence of Experts) are used interchangeably in the codebase 1. Zhu Y, Wong J, Mandlekar A, Martín-Martín R, Joshi A, Lin K, Maddukuri A, Nasiriany S, Zhu Y. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. arXiv:2009.12293 [cs.RO]; 2025. Available at: https://arxiv.org/abs/2009.12293.
研究动机与目标
- 提供一个灵活的、模块化的框架,用于创建机器人操作环境和任务。
- 提供现成的、真实感的机器人控制器和学习管线,以降低进入门槛。
- 提供标准化的基准任务,以实现严格评估和可重复性。
- 支持多模态感知和人类演示,以提升学习效果和数据收集。
- 实现跨多种机器人和任务的数据驱动机器人算法的可重复基准评估。
提出的方法
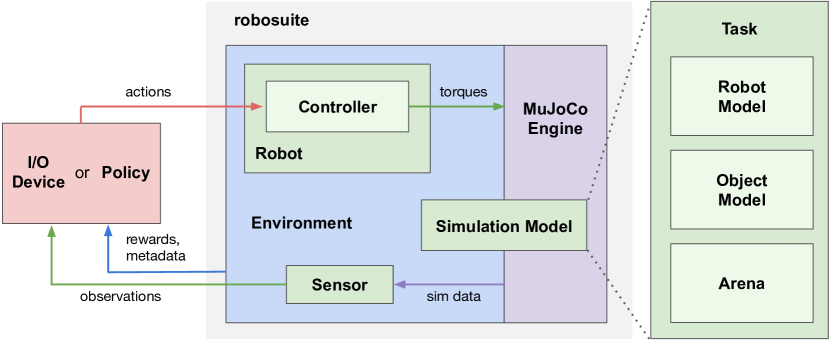
- 两种主要 API:用于定义仿真环境的建模 API,以及用于与物理引擎接口的仿真 API。
- 任务组合:每个 Task 由 RobotModel、Arena 和 Object Model 组成,形成用于 MuJoCo 的 MJCF 模型。
- 环境对象提供 OpenAI Gym 风格的接口和可配置属性(例如 has_renderer、horizon、reward_shaping)。
- 机器人、控制器和传感器是模块化的,支持机器人手臂、夹具和控制方案的即插即用组合。
- 传感器提供多模态观测(RGB-D、本体感知、力矩等),环境提供奖励和任务元数据。
- 输入/输出设备(如键盘、SpaceMouse)支持实时远程操作和用于演示及调试的数据采集。
- 一个基准套件在九个标准化任务上评估学习算法(如 SAC),并具有可重复的实验设置。

实验结果
研究问题
- RQ1模块化框架如何在可重复基准测试的前提下,支持多样化的机器人操作任务?
- RQ2控制器选择和动作空间对操作任务的学习效率有何影响?
- RQ3标准化环境套件是否能实现对数据驱动机器人方法的公平比较和进展跟踪?
- RQ4多模态感知与人类演示如何集成到仿真机器人学习管线中?
- RQ5哪些实际配置(机器人、夹具、控制器)在跨任务中能最大化学习性能?
主要发现
- robosuite v1.0 提供七种机器人模型、八种夹具、六种控制器,以及九个标准化任务。
- 使用 SAC 进行的基准测试在特定设置下解决九个环境中的三个(Block Lifting、Door Opening、Two Arm Peg-in-Hole)。
- 在至少某些任务中,操作空间控制器比关节-速度控制器提高了学习效率,表明任务空间探索的优势。
- 双臂任务展示了在同一框架中使用多台机器人(Panda 或 Sawyer)进行协同操作的能力。
- 该框架支持过程化环境生成以及可重复实验结果的仓库。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。