[论文解读] Multimodal Chain-of-Thought Reasoning in Language Models
本文提出 Multimodal-CoT,一种两阶段微调框架,能够从文本和视觉输入生成推理理由,然后利用这些多模态推理来推断答案,在ScienceQA上以1B模型实现了最先进水平。
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
研究动机与目标
- 激励多模态(文本+视觉)链路思维(CoT)推理,以改进答案推断。
- 探究为何1B模型在CoT方面存在困难,以及视觉如何减轻推理陷阱。
- 提出一个两阶段微调框架,将理由生成与答案推断分离。
- 在ScienceQA基准上评估该方法,并与仅语言和更大模型进行对比。
提出的方法
- 分两阶段对一个基于 T5 的文本到文本 Transformer 进行微调:理由生成与答案推断。
- 使用一个视觉编码器(DETR)提取图像特征,并通过一个门控融合机制将其与语言表示融合。
- 在第一阶段,从语言+视觉输入生成一个理由 R;在第二阶段,在原始输入和 R 的条件下推断答案。
- 采用两阶段训练方案,对 ScienceQA 注释的理由和答案进行监督学习。
- 通过语言与视觉表示之间的基于注意力的交互将视觉特征引入,从而提升理由质量和答案准确性。
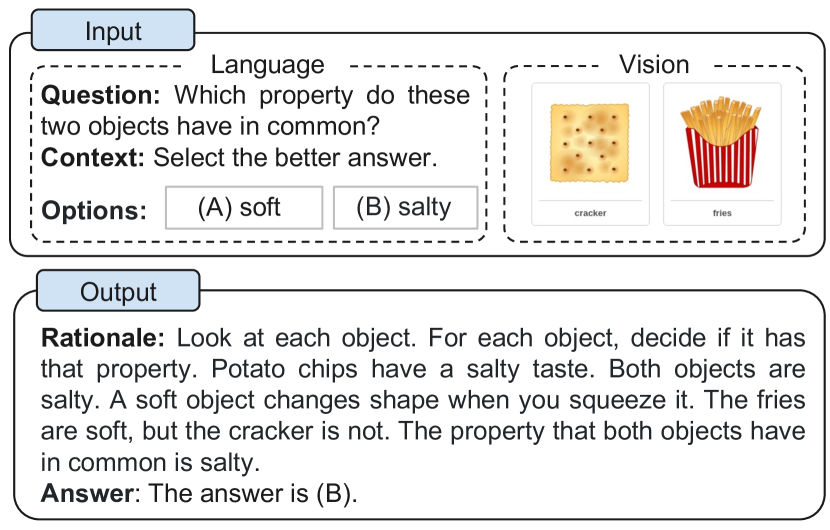
实验结果
研究问题
- RQ1多模态(文本+视觉)CoT 推理是否能在多模态问答基准上超越语言专用的CoT?
- RQ2当提供多模态输入时,1B 模型是否能从两阶段的理由生成与答案推断框架中受益?
- RQ3使用视觉特征(DETR)与使用字幕在理由质量和最终答案上的影响有何不同?
- RQ4多模态融合(带注意力的门控融合)相较于文本单一基线,对推理和准确性有何影响?
主要发现
| Model | Size | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| MCAN (2019) | 95M | 56.08 | 46.23 | 58.09 | 59.43 | 51.17 | 55.40 | 51.65 | 59.72 | 54.54 |
| Top-Down (2018) | 70M | 59.50 | 54.33 | 61.82 | 62.90 | 54.88 | 59.79 | 57.27 | 62.16 | 59.02 |
| BAN (2018) | 112M | 60.88 | 46.57 | 66.64 | 62.61 | 52.60 | 65.51 | 56.83 | 63.94 | 59.37 |
| DFAF (2019) | 74M | 64.03 | 48.82 | 63.55 | 65.88 | 54.49 | 64.11 | 57.12 | 67.17 | 60.72 |
| ViLT (2021) | 113M | 60.48 | 63.89 | 60.27 | 63.20 | 61.38 | 57.00 | 60.72 | 61.90 | 61.14 |
| Patch-TRM (2021) | 90M | 65.19 | 46.79 | 65.55 | 66.96 | 55.28 | 64.95 | 58.04 | 67.50 | 61.42 |
| VisualBERT (2019) | 111M | 59.33 | 69.18 | 61.18 | 62.71 | 62.17 | 58.54 | 62.96 | 59.92 | 61.87 |
| UnifiedQA Base (2020) | 223M | 68.16 | 69.18 | 74.91 | 63.78 | 61.38 | 77.84 | 72.98 | 65.00 | 70.12 |
| UnifiedQA Base + CoT | 223M | 71.00 | 76.04 | 78.91 | 66.42 | 66.53 | 81.81 | 77.06 | 68.82 | 74.11 |
| GPT-3.5 (2020) | 175B | 74.64 | 69.74 | 76.00 | 74.44 | 67.28 | 77.42 | 76.80 | 68.89 | 73.97 |
| GPT-3.5 + CoT | 175B | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| Multimodal-CoT Base | 223M | 87.52 | 77.17 | 85.82 | 87.88 | 82.90 | 86.83 | 84.65 | 85.37 | 84.91 |
| Multimodal-CoT Large | 738M | 95.91 | 82.00 | 90.82 | 95.26 | 88.80 | 92.89 | 92.44 | 90.31 | 91.68 |
- 在 ScienceQA 上,带视觉特征的 Multimodal-CoT 比 GPT-3.5 提高 16 个百分点(Large 设置下为 91.68% 对 75.17%)。
- 两阶段 Multimodal-CoT 的准确率高于直接预测答案的一阶段基线。
- 使用视觉特征(DETR)显著提升理由质量(RougeL)和最终答案准确率(84.91%),减少幻觉引起的错误。
- 不同视觉特征影响性能;DETR 提供显著增益,而 CLIP 和 ResNet 在此设置中较差。
- 该方法在不同骨干模型(UnifiedQA Base/Large, FLAN-T5 Base/Large)上具有泛化能力,并在 1B- 到 ~0.7B 参数规模仍然有效。
- 消融显示若移除两阶段设计或视觉特征,性能下降(如无 Two-Stage Framework 平均降至 82.57;无 Vision Features 平均降至 70.53)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。