[论文解读] MultiModal-GPT: A Vision and Language Model for Dialogue with Humans
MultiModal-GPT 在 OpenFlamingo 上使用 LoRA 进行多模态对话微调,结合统一的视觉-语言与仅语言指令数据,以提升多轮人机对话能力。
We present a vision and language model named MultiModal-GPT to conduct multi-round dialogue with humans. MultiModal-GPT can follow various instructions from humans, such as generating a detailed caption, counting the number of interested objects, and answering general questions from users. MultiModal-GPT is parameter-efficiently fine-tuned from OpenFlamingo, with Low-rank Adapter (LoRA) added both in the cross-attention part and the self-attention part of the language model. We first construct instruction templates with vision and language data for multi-modality instruction tuning to make the model understand and follow human instructions. We find the quality of training data is vital for the dialogue performance, where few data containing short answers can lead the model to respond shortly to any instructions. To further enhance the ability to chat with humans of the MultiModal-GPT, we utilize language-only instruction-following data to train the MultiModal-GPT jointly. The joint training of language-only and visual-language instructions with the \emph{same} instruction template effectively improves dialogue performance. Various demos show the ability of continuous dialogue of MultiModal-GPT with humans. Code, dataset, and demo are at https://github.com/open-mmlab/Multimodal-GPT
研究动机与目标
- 推动开发一个能够遵循多样化视觉-语言指令的多模态对话代理的开发。
- 通过在冻结的基础模型上利用低秩自适应(LoRA)实现高效微调。
- 开发统一的指令模板,以在视觉-语言数据和仅语言数据上进行训练。
- 研究数据质量对对话性能的影响,并识别可能降低性能的数据集。
- 通过定性演示和评估展示连续的人类般对话能力。
提出的方法
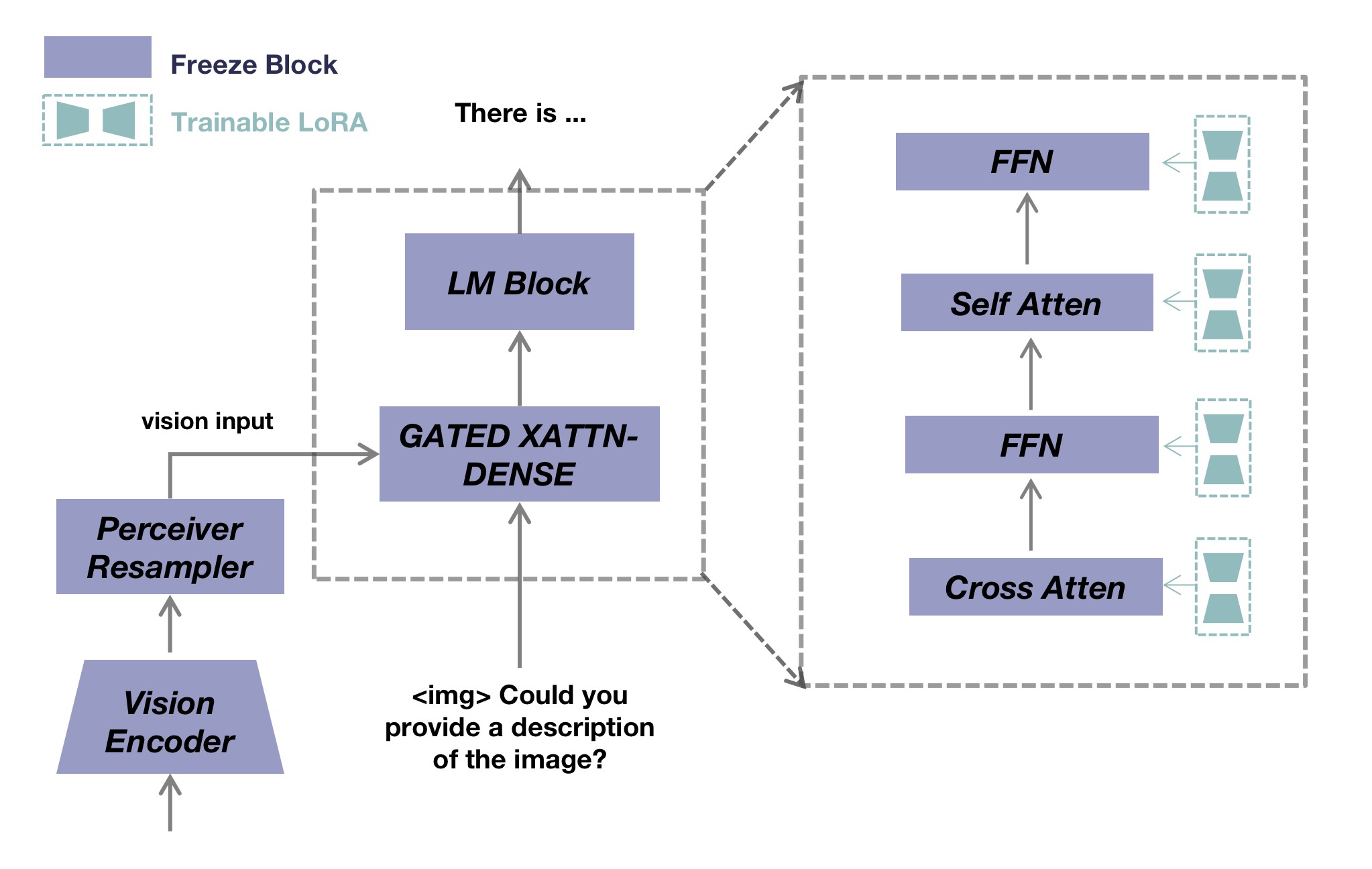
- 基础架构基于 OpenFlamingo,配备来自 CLIP 的视觉编码器和将 perceiver 重采样输入给 LLaMA 语言解码器。
- 在微调过程中,LoRA 应用于语言解码器中的自注意力、交叉注意力和前馈网络。
- 使用统一的指令模板将语言-仅数据和视觉-语言数据转换为共同的训练格式。
- 联合训练同时使用语言-仅指令数据(如 Dolly 15k、Alpaca GPT4)和视觉-语言指令数据(如 LLaVA、Mini-GPT4、A-OKVQA、COCO Caption、OCR VQA)。
- 只有回应和 EOS 令牌参与损失计算,模型预测下一个令牌。
- 训练细节包括八张 A100 GPU、一个周期、每张 GPU 的批大小为 1、梯度累积,以及 LoRA 每 16 次迭代更新一次。
实验结果
研究问题
- RQ1统一的视觉-语言与仅语言指令模板是否能够通过联合训练实现有效的多模态对话?
- RQ2训练数据的质量与组成如何影响多模态对话应答的质量与长度?
- RQ3冻结基础模型并对目标组件使用 LoRA 是否能带来稳健的多模态对话性能?
- RQ4包含多样化视觉-语言数据集对持续对话能力有何影响?
- RQ5模型能否维持连贯的多轮对话并完成计数、描述和一般查询等任务?
主要发现
- 数据质量对对话性能有关键影响;回答较短的数据集可能导致模型回复过于简短。
- 与仅使用其中一种相比,联合使用视觉-语言与语言-仅指令数据显著提升对话能力。
- 排除低质量或过于简短的数据集(如 VQA v2.0、OKVQA、GQA、CLEVR、NLVR)可避免匆促给出简短答案并提升用户友好性。
- 统一的指令模板有效地利用两种数据模态来提升多模态理解和应答生成。
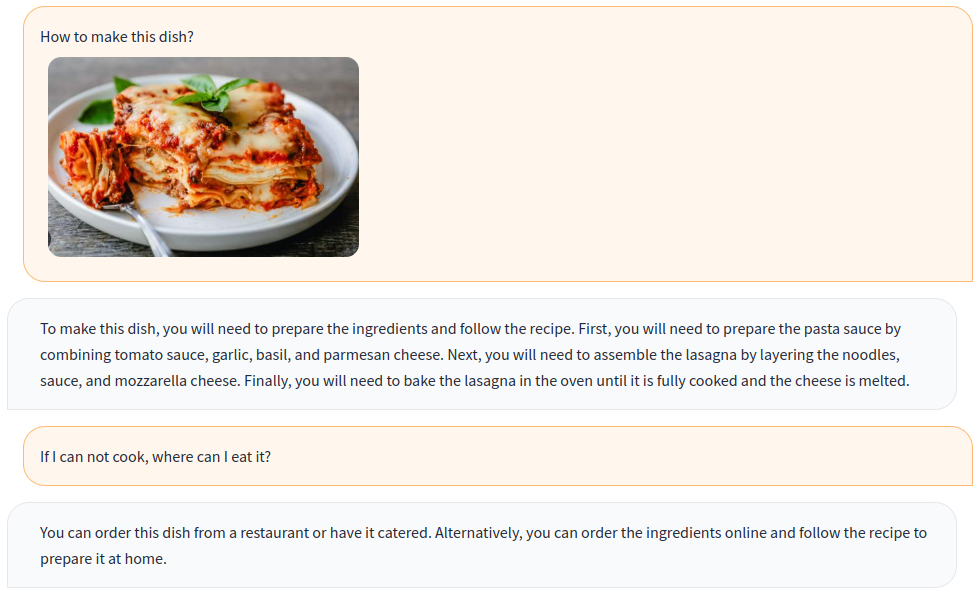
- 该方法在示范的多种任务中展现了与人类的连续对话(如食谱、用餐建议、OCR、计数等)。
- 代码、数据集和演示可在项目仓库 https://github.com/open-mmlab/Multimodal-GPT 获取。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。