[论文解读] MultiSpeech: Multi-Speaker Text to Speech with Transformer
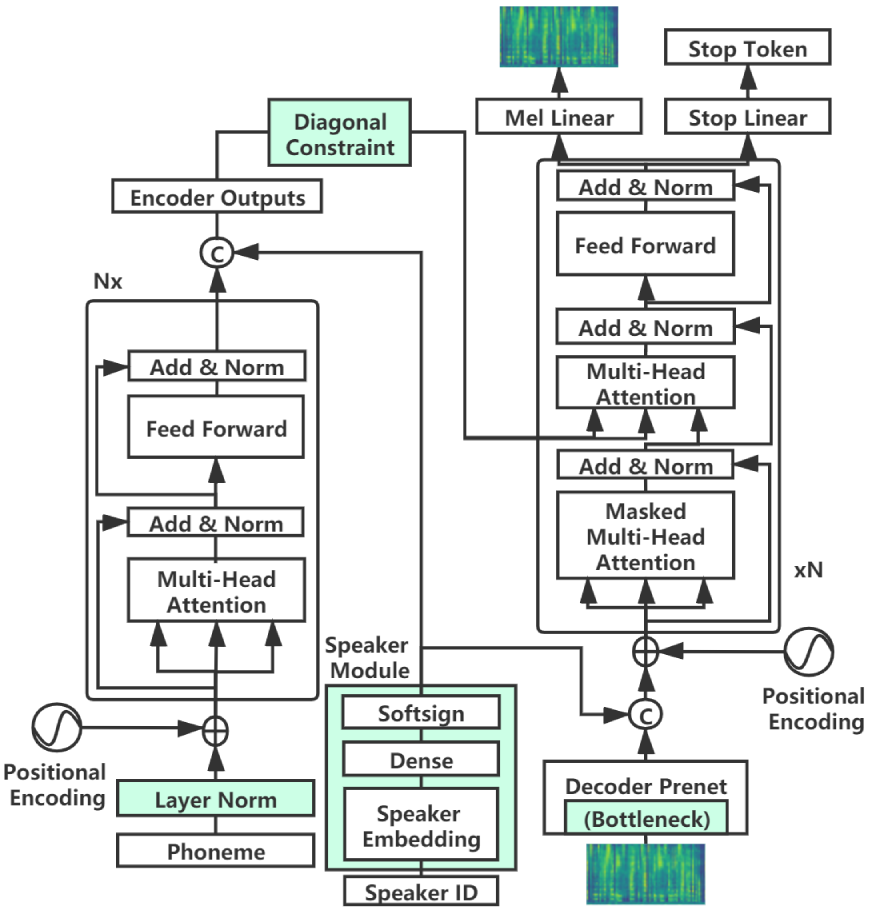
MultiSpeech 引入了一个鲁棒的多说话人 Transformer TTS,包含三项技术——对角注意力约束、对说话人音素嵌入的编码器层归一化,以及一个小型解码器预网瓶颈——以改善文本到语音的对齐与语音质量;它也作为教师训练一个快速的多说话人 FastSpeech 模型。
Transformer-based text to speech (TTS) model (e.g., Transformer TTS~\cite{li2019neural}, FastSpeech~\cite{ren2019fastspeech}) has shown the advantages of training and inference efficiency over RNN-based model (e.g., Tacotron~\cite{shen2018natural}) due to its parallel computation in training and/or inference. However, the parallel computation increases the difficulty while learning the alignment between text and speech in Transformer, which is further magnified in the multi-speaker scenario with noisy data and diverse speakers, and hinders the applicability of Transformer for multi-speaker TTS. In this paper, we develop a robust and high-quality multi-speaker Transformer TTS system called MultiSpeech, with several specially designed components/techniques to improve text-to-speech alignment: 1) a diagonal constraint on the weight matrix of encoder-decoder attention in both training and inference; 2) layer normalization on phoneme embedding in encoder to better preserve position information; 3) a bottleneck in decoder pre-net to prevent copy between consecutive speech frames. Experiments on VCTK and LibriTTS multi-speaker datasets demonstrate the effectiveness of MultiSpeech: 1) it synthesizes more robust and better quality multi-speaker voice than naive Transformer based TTS; 2) with a MutiSpeech model as the teacher, we obtain a strong multi-speaker FastSpeech model with almost zero quality degradation while enjoying extremely fast inference speed.
研究动机与目标
- 在嘈杂且说话人多样的条件下,改进多说话人 Transformer TTS 的文本转语音对齐。
- 提出稳定并提升合成质量的结构与训练技术。
- 实现快速、可扩展的多说话人推理,并实现对 FastSpeech 的知识蒸馏。
提出的方法
- 在编码器-解码器注意力上引入对角约束,以促进单调、对角的对齐。
- 对编码器音素嵌入应用层归一化,以在加入位置嵌入前保留位置信息。
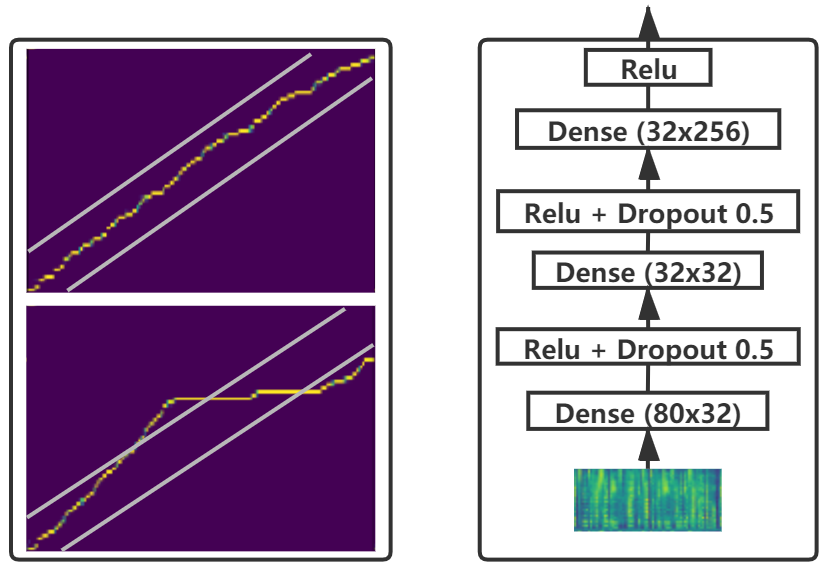
- 使用一个小的解码器预网瓶颈(如 80-32-32-256)以防止从相邻帧复制并强制文本驱动的预测。
- 在自回归推理中结合注意力滑动窗口以维持对齐的推进。
- 在多说话人数据集(VCTK、LibriTTS)上训练 MultiSpeech,使用 Transformer 块(每个 4 层,隐藏维度 256)。
- 使用 WaveNet 作为声码器进行波形合成并进行 MOS 评价;通过教师-学生蒸馏扩展到 FastSpeech。
实验结果
研究问题
- RQ1对角注意力约束是否可以改善多说话人 Transformer TTS 的对齐学习?
- RQ2对音素嵌入应用层归一化是否能改善位置信息和对齐质量?
- RQ3预网瓶颈是否能够防止帧复制并促进文本驱动的解码?
- RQ4MultiSpeech 能否作为 FastSpeech 的有效教师实现快速多说话人 TTS 而不降低质量?
主要发现
| Setting | VCTK MOS (95% CI) | LibriTTS MOS (95% CI) |
|---|---|---|
| GT | 4.04±0.14 | |
| GT mel + Vocoder | 3.89±0.20 | |
| Transformer based TTS | 2.64±0.35 | |
| MultiSpeech | 3.65±0.14 | |
| GT | 4.14±0.16 | |
| GT mel + Vocoder | 3.90±0.08 | |
| Transformer based TTS | 1.49±0.09 | |
| MultiSpeech | 2.95±0.14 |
- MultiSpeech 在 VCTK 和 LibriTTS 上相比朴素的基于 Transformer 的多说话人 TTS 获得更高的 MOS。
- 在 VCTK 上,MultiSpeech MOS = 3.65 (0.14),对角率 r = 0.694;在 LibriTTS 上 MOS = 2.95 (0.14)。
- 消融实验显示去除对角约束、层归一化或预网瓶颈会降低 MOS 和/或对角率;去除三者会将 MOS 降至 2.64 (0.35) 且 r 降至 0.366。
- 对编码器输入进行层归一化(LN)提供更高的对角注意率(r = 0.694),高于可学习权重(LW)和基线(分别为 0.506 和 0.637)。
- 以 MultiSpeech 作为教师时,在 VCTK 上的多说话人 FastSpeech 模型达到 MOS 3.53 (0.22),相对于 GT 4.02 (0.09) 和 FastSpeech 基线 3.45 (0.13),推理速度显著提高。
- MultiSpeech 在 GT mel + Vocoder 上的 MOS 接近 GT。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。