QUICK REVIEW
[论文解读] Multivariate Time Series Classification Using Dynamic Time Warping Template Selection for Human Activity Recognition
Skyler Seto, Wenyu Zhang|arXiv (Cornell University)|Dec 21, 2015
Context-Aware Activity Recognition Systems参考文献 14被引用 31
一句话总结
本文提出了一种基于动态时间规整(DTW)的模板选择方法,用于人体活动识别中的多变量时间序列分类,避免了复杂的特征提取和领域知识。通过使用改进的DTW对运动数据进行聚类并构建活动模板,该方法在噪声环境和新受试者条件下,实现了与传统特征提取方法相当或更优的准确率。
ABSTRACT
Accurate and computationally efficient means for classifying human activities have been the subject of extensive research efforts. Most current research focuses on extracting complex features to achieve high classification accuracy. We propose a template selection approach based on Dynamic Time Warping, such that complex feature extraction and domain knowledge is avoided. We demonstrate the predictive capability of the algorithm on both simulated and real smartphone data.
研究动机与目标
- 开发一种计算高效且准确的方法,利用智能手机传感器数据对人类活动进行分类。
- 消除人体活动识别(HAR)中对复杂特征提取和领域专业知识的依赖。
- 从多变量时间序列数据中构建可解释且具有视觉意义的活动模板。
- 提高对噪声的鲁棒性,并增强对训练数据中未出现的新测试受试者的泛化能力。
- 在真实世界UCI HAR数据和合成的噪声数据上证明该方法的有效性。
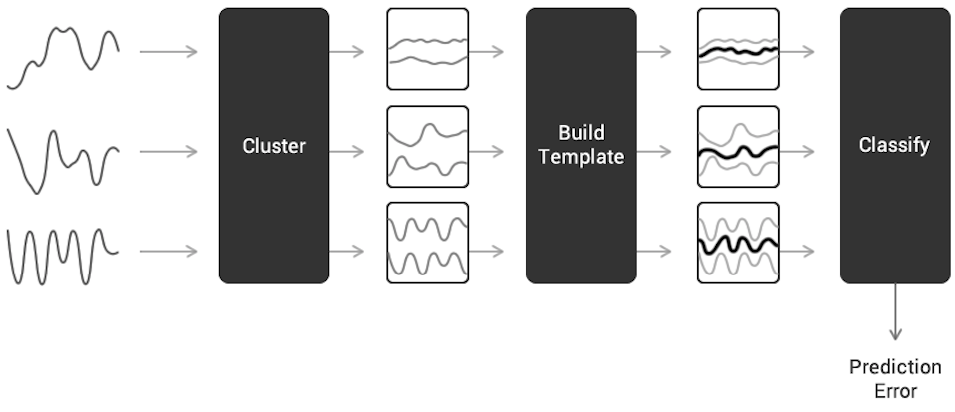
提出的方法
- 将动态时间规整(DTW)修改为相似性度量,以提高多变量时间序列的准确率和计算效率。
- 使用基于DTW的聚类将相似的运动序列分组为代表不同人类活动的聚类。
- 通过DBA或DPA从每个聚类中构造时间序列平均值作为活动模板,以表示典型活动模式。
- 应用基于子序列的DTW变体(DTWsubseq)以增强相似性度量和分类性能。
- 引入阈值参数'cut'以控制模板生成,较低值可通过减少过拟合来提高准确率。
- 通过计算测试序列与所有模板之间的DTW距离来使用模板进行分类,并将最近似配对的模板作为预测结果。
![Figure 1: DTW image from [ 12 ] showing the alignment procedure. The two original time series shown on the left (dotted) and bottom (solid) of the image on the right are shown aligned on the left image according to the optimal path shown as the dark black line on the right.](https://ar5iv.labs.arxiv.org/html/1512.06747/assets/DTWpic.jpg)
实验结果
研究问题
- RQ1基于DTW的模板选择方法是否能在人体活动识别中实现与传统特征提取方法相当或更优的分类准确率?
- RQ2在存在噪声以及针对训练集中未包含的新个体数据时,该方法的性能如何?
- RQ3与标准DTW相比,使用DTWsubseq或改进的DTW是否能提高分类准确率?
- RQ4在模板构建中,使用DBA(动态时间规整巴氏平均)与DPA(基于DTW的成对平均)是否存在性能差异?
- RQ5'cut'阈值参数如何影响分类准确率和模型泛化能力?
主要发现
- 该方法在UCI HAR数据集上实现了0.860的准确率(动态活动下为0.890),与特征提取方法相当。
- 在合成数据上,使用DTWsubseq与DPA及cut=0.25时,准确率达到0.700,优于特征提取方法(0.67)。
- 基于DBA的模板在间歇性噪声下显著优于基于DPA的模板,即使在噪声区域也能保持形状。
- 降低'cut'参数在真实和合成数据集上均一致地提高了准确率,表明泛化能力增强。
- 在所有配置中,DTWsubseq均优于标准DTW,表明其在分类中具有更优的相似性度量能力。
- 该方法在新受试者和噪声数据上表现出强泛化能力,在合成评估中准确率高于特征提取方法。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。