[论文解读] Muse: Text-To-Image Generation via Masked Generative Transformers
Muse 引入一种使用掩码令牌预测的离散潜在空间的文本到图像 Transformer,在冻结的 LLM 嵌入条件下,实现最先进的 FID/CLIP,同时实现快速并行解码和零样本 编辑。
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
研究动机与目标
- 通过在离散令牌空间中利用掩码建模来提升文本到图像合成。
- 整合预训练语言模型嵌入,以提高语义保真度和空间推理。
- 通过对离散令牌进行并行解码,相比扩散/自回归基线,提升推理效率。
- 在不进行微调的情况下,实现零样本图像编辑(图像修复、扩展、无掩码编辑)。
- 在 CC3M 和 COCO 上进行评估,以展示最先进的质量与对齐。
提出的方法
- 使用双重 VQGAN 标记器将图像编码为离散令牌(256×256,f=16;512×512,f=8)。
- 将图像解码器条件化为冻结的 T5-XXL 文本嵌入,以提供丰富的语言条件。
- 使用基本的掩码 Transformer,通过对文本嵌入的 cross-attention 和图像令牌之间的自注意力,来预测被掩码的图像令牌。
- 使用从余弦调度中采样的可变掩码率进行训练,以促进稳健的令牌预测并实现灵活的采样。
- 随后使用超分辨率 Transformer 将低分辨率令牌转换为高分辨率令牌,条件化为文本嵌入。
- 在采样期间应用无分类器引导,以改善文本—图像对齐并允许负提示。
- 执行迭代并行解码以在每步预测多个令牌,使推理速度比自回归或扩散模型更快。
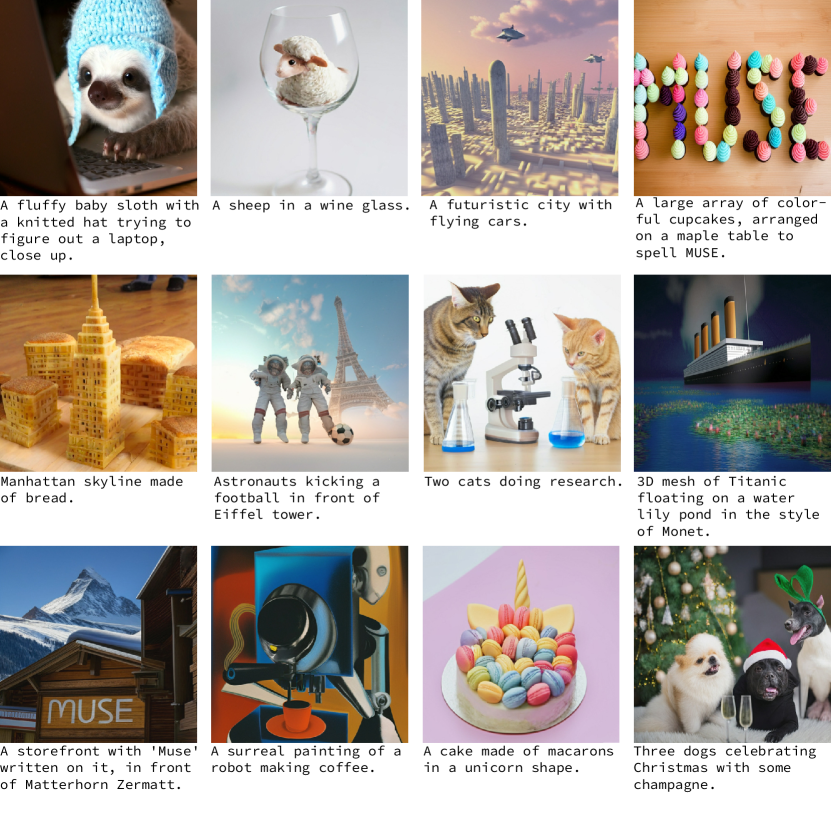
实验结果
研究问题
- RQ1在预训练的 LLM 嵌入条件下的掩码、离散令牌图像模型,是否能达到最先进的图像保真度和文本对齐?
- RQ2基底和超分辨率令牌 Transformer 的组合在 256×256 和 512×512 输出下表现如何?
- RQ3相比扩散/自回归基线,在离散令牌框架中通过并行解码可以实现哪些推理效率提升?
- RQ4在不进行微调的情况下,零样本编辑(修复、扩展、无掩码编辑)可以达到多大程度?
- RQ5在保持快速采样的同时,Muse 在 CC3M 和 COCO 上在 FID 与 CLIP 方面的表现如何?
主要发现
| 模型 | 模型类型 | 参数 | FID-30K | 零样本 | CLIP |
|---|---|---|---|---|---|
| VQGAN | Autoregressive | 600M | 28.86 | 0.20 | - |
| ImageBART | Diffusion+Autogressive | 2.8B | 22.61 | 0.23 | - |
| LDM-4 | Diffusion | 645M | 17.01 | 0.24 | - |
| RQ-Transformer | Autoregressive | 654M | 12.33 | 0.26 | - |
| Draft-and-revise | Non-autoregressive | 654M | 9.65 | 0.26 | - |
| Muse(base model) | Non-Autoregressive | 632M | 6.8 | 0.25 | - |
| Muse(base + super-res) | Non-Autoregressive | 632M + 268M | 6.06 | 0.26 | - |
- Muse 在 CC3M 上实现了最先进的 FID(6.06,632M base + 268M super-res 令牌)。
- Muse-3B 在 COCO 的零样本 FID 为 7.88,CLIP 0.32。
- Muse 在人类对齐提示方面优于同类模型,在用户研究中,提示-图像对齐约比 Stable Diffusion 高出约 2.7×。
- 由于离散令牌和并行解码,推理速度显著快于扩散或自回归模型(例如,在 TPUv4 上每张 256×256–512×512 图像约 0.5–1.3s)。
- 直接启用零样本图像编辑(修复、扩展和无掩码编辑),无需微调或反演,通过条件令牌重采样实现。
- 定性结果显示对基数、构图、风格和文本渲染有良好理解,尽管对于较长多词短语和高基数仍存在挑战。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。