[论文解读] MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
MVSplat 引入基于成本-体积的前馈式三维高斯点化模型,该模型从稀疏多视图图像中学习高斯中心和参数,在显著减少参数数量、推理更快的情况下实现了优于现有方法的渲染质量。
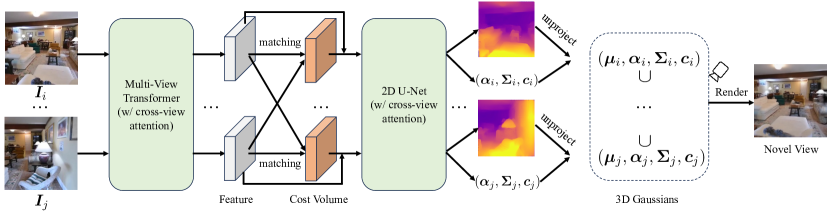
We introduce MVSplat, an efficient model that, given sparse multi-view images as input, predicts clean feed-forward 3D Gaussians. To accurately localize the Gaussian centers, we build a cost volume representation via plane sweeping, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We also learn other Gaussian primitives' parameters jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussians via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, MVSplat achieves state-of-the-art performance with the fastest feed-forward inference speed (22~fps). More impressively, compared to the latest state-of-the-art method pixelSplat, MVSplat uses $10 imes$ fewer parameters and infers more than $2 imes$ faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
研究动机与目标
- 从极度稀疏的多视图输入中推动高效的三维场景重建与新视图合成。
- 利用三维高斯点化表示实现快速、可微分的渲染。
- 引入基于代价体积的深度与几何学习模块,以定位高斯中心。
- 在光度监督下,与中心一起预测高斯参数(不透明度、协方差、颜色)。
- 展示相较于先前方法在跨数据集泛化性和效率方面的显著优势。
提出的方法
- 通过在三维中进行平面扫描来构建代价体积,以捕捉深度候选的跨视图特征相似性。
- 使用多视图 Transformer 提取并融合跨视图的特征,实现视图一致的深度预测。
- 用轻量级的二维 U-Net 和跨视图注意力对代价体积进行细化,以处理无纹理区域。
- 对深度图进行反投影以获得三维高斯中心,并预测不透明度、协方差(尺度和旋转)以及颜色(球谐函数)。
- 使用预测的参数通过可微分的三维高斯点化渲染新视图。
- 端到端训练,通过渲染图像与真实图像之间的光度损失。
实验结果
研究问题
- RQ1是否可以通过代价体积驱动的前馈模型,在稀疏视图下提升场景尺度重建的几何与外观质量?
- RQ2通过跨视图代价体积联合学习三维高斯中心和参数,是否能带来更好的跨视图一致性和泛化?
- RQ3在 RealEstate10K、ACID 和 DTU 上,MVSplat 在准确性、速度和参数效率方面与最先进方法相比如何?
- RQ4如代价体积、跨视图注意力以及细化 U-Net 等组件对最终性能的影响是什么?
主要发现
| 方法 | 时间(秒) | 参数量(M) | RealEstate10K PSNR | RealEstate10K SSIM | RealEstate10K LPIPS | ACID PSNR | ACID SSIM | ACID LPIPS |
|---|---|---|---|---|---|---|---|---|
| pixelNeRF | 5.299 | 28.2 | 20.43 | 0.589 | 0.550 | 20.97 | 0.547 | 0.533 |
| GPNR | 13.340 | 9.6 | 26.10 | 0.858 | 0.143 | 25.28 | 0.764 | 0.332 |
| AttnRend | 1.325 | 125.1 | 24.78 | 0.820 | 0.213 | 26.88 | 0.799 | 0.218 |
| MuRF | 0.186 | 5.3 | 26.10 | 0.858 | 0.143 | 28.09 | 0.841 | 0.155 |
| pixelSplat | 0.104 | 125.4 | 25.89 | 0.858 | 0.142 | 28.14 | 0.839 | 0.150 |
| MVSplat | 0.044 | 12.0 | 26.39 | 0.869 | 0.128 | 28.25 | 0.843 | 0.144 |
- 在 RealEstate10K 和 ACID 基准测试的 PSNR、SSIM 和 LPIPS 上实现了最先进的渲染质量。
- 前馈推理速度为 22 帧/秒,参数量约 12.0M,在速度和效率上优于 pixelSplat。
- 参数量最多少用 10 倍,推理速度比 pixelSplat 提高超过 2 倍,同时实现更好的外观和几何质量。
- 基于代价体积的编码器至关重要;移除后性能显著下降(如 PSNR 降幅 >3dB)。
- 跨视图注意力和 2D U-Net 细化显著改善几何并处理具有挑战性的区域。
- 在零-shot 跨数据集泛化方面,MVSplat 相较于 pixelSplat 更强,对 LPIPS 更好且对领域移位更鲁棒。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。