[论文解读] Network Analytics for Anti-Money Laundering -- A Systematic Literature Review and Experimental Evaluation
对 AML 的网络分析(NA)进行系统性文献综述,涵盖 97 篇论文;并提出一个实验框架,对 Elliptic 数据集中的主流 NA 方法进行基准评估,结果表明图神经网络取得最佳性能。
Money laundering presents a pervasive challenge, burdening society by financing illegal activities. The use of network information is increasingly being explored to effectively combat money laundering, given it involves connected parties. This led to a surge in research on network analytics for anti-money laundering (AML). The literature is, however, fragmented and a comprehensive overview of existing work is missing. This results in limited understanding of the methods to apply and their comparative detection power. This paper presents an extensive and unique literature review, based on 97 papers from Web of Science and Scopus, resulting in a taxonomy following a recently proposed fraud analytics framework. We conclude that most research relies on expert-based rules and manual features, while deep learning methods have been gaining traction. This paper also presents a comprehensive framework to evaluate and compare the performance of prominent methods in a standardized setup. We compare manual feature engineering, random walk-based, and deep learning methods on two publicly available data sets. We conclude that (1) network analytics increases the predictive power, but caution is needed when applying GNNs in the face of class imbalance and network topology, and that (2) care should be taken with synthetic data as this can give overly optimistic results. The open-source implementation facilitates researchers and practitioners to extend this work on proprietary data, promoting a standardised approach for the analysis and evaluation of network analytics for AML.
研究动机与目标
- 在法币与加密货币场景下提供对 AML 的网络分析的广泛系统性综述。
- 开发并发布一个统一的实验框架,以在 AML 任务上比较 NA 方法。
- 在统一设置下评估传统特征基、随机游走和图神经网络等方法。
- 通过提供可复现和可扩展的开源代码来促进可重复性。
提出的方法
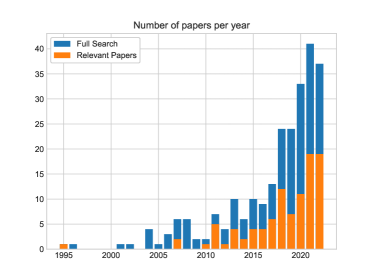
- 在 Web of Science 与 Scopus 上进行系统性文献回顾,识别出 97 篇论文。
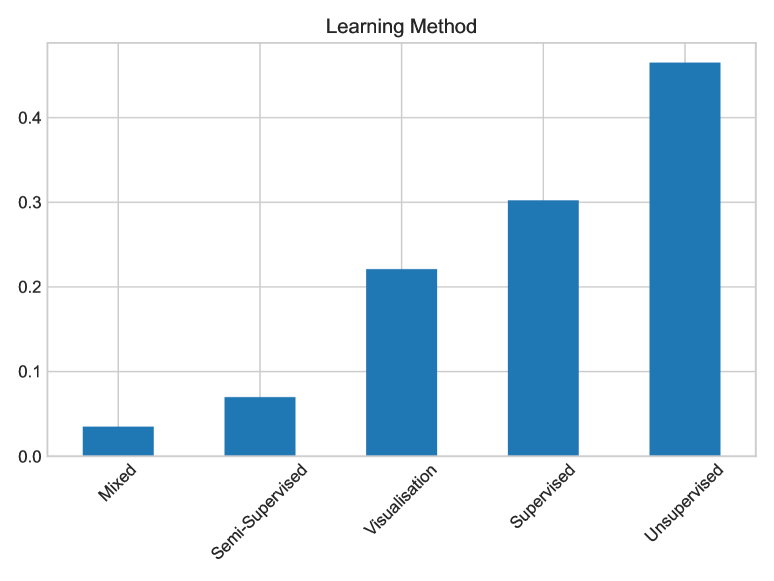
- 对论文进行五维分类:发表数据、学习方法、评估指标、目标、数据类型。
- 构建一个统一的实验框架,应用于 Elliptic 数据集。
- 在统一设置中实现手工特征工程、基于随机游走的方法以及深度学习 GNNs。
- 开源代码仓库,以实现复现与扩展。
实验结果
研究问题
- RQ1在文献中 AML 的主导网络分析方法是什么(有监督、无监督和可视化)?
- RQ2在统一的实验设置下,不同 NA 方法在真实 AML 数据(Elliptic 数据集)上的表现如何?
- RQ3哪些数据与评估实践会影响 AML 的 NA 的可比性和可复现性?
主要发现
- 与非 NA 基线相比,网络分析提高了 AML 模型的预测能力。
- 在 Elliptic 数据集上,图神经网络在所评估的 NA 方法中取得最佳结果。
- 开源数据(加密货币)在跨数据集评估中占主导地位,而非加密货币的 AML 研究常使用专有数据。
- 大多数研究依赖基于中心性的特征;在 AML NA 语境中较少有工作应用最先进的深度学习。
- 评估凸显数据可用性、标签不平衡以及需要标准化基准的问题。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。