[论文解读] Noise2Music: Text-conditioned Music Generation with Diffusion Models
Noise2Music 训练级联扩散模型以在 24 kHz 生成 30 秒、文本条件的音乐,使用频谱图或低保真波形作为中间表示,并通过大语言模型对语义对齐进行支撑。
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
研究动机与目标
- 在大规模上推动并实现高质量的文本条件音乐生成。
- 开发一个基于扩散的管线,生成以自由文本提示为条件的 30 秒音乐。
- 利用大语言模型与音乐-文本嵌入来使音频中的细粒度语义属性得到支撑。
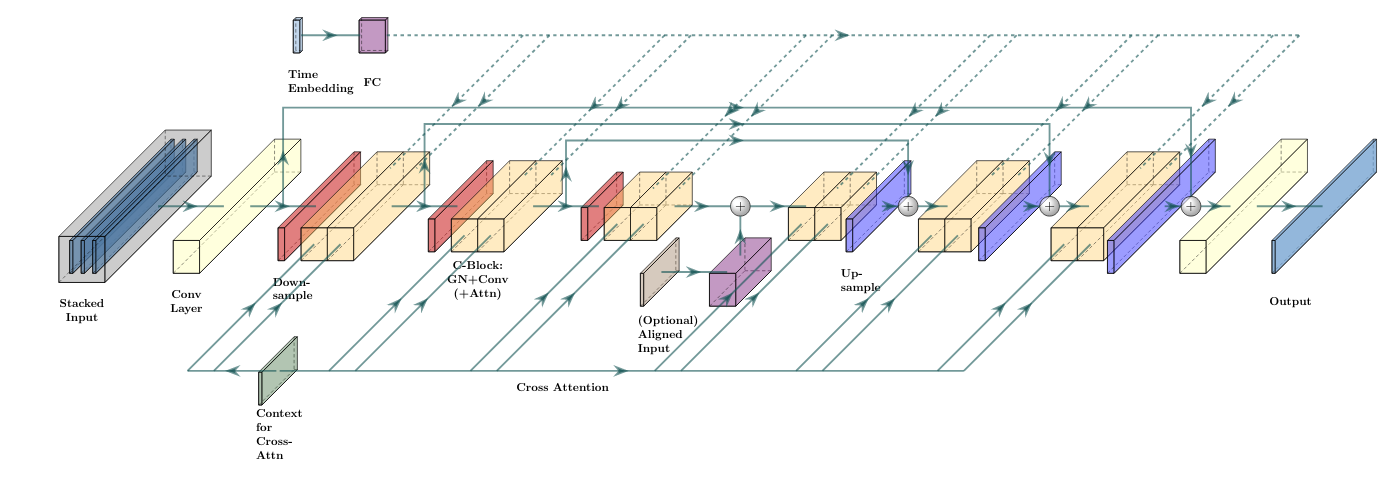
提出的方法
- 训练一个由生成器输出中间表示、以及对中间表示进行细化以得到高保真音频的级联扩散模型。
- 探索两种中间表示:(i) 对数梅尔频谱图以及 (ii) 3.2 kHz 波形。
- 通过与预训练语言模型编码器(T5)的跨注意力对文本进行条件化扩散模型。
- 使用最终的超分辨率级联器从 16 kHz 中间音频生成 24 kHz 音频。
- 利用 MuLan-LM 的伪标签来创建大规模的文本-音频对,并构建 MuLaMCap 以丰富训练数据的多样性。
- 在不同的训练和增强策略下训练四个一维 U-Net 扩散模型(波形生成器、波形级联器、谱图生成器、谱图声码器)和一个超分辨率级联器。
- 推理阶段使用 CFG、前/后/前重加权去噪计划,并通过调整随机性以在质量与多样性之间取得平衡。
实验结果
研究问题
- RQ1扩散式架构是否能够在高保真度的前提下生成以任意文本提示为条件的较长(30 秒)音乐片段?
- RQ2通过大语言模型和音乐-文本嵌入进行支撑,是否能够在生成的音乐中实现基于风格、节奏、情感、时代等的细粒度语义控制?
- RQ3中间表示(谱图 vs 波形)对文本条件音乐生成的质量与语义对齐有何影响?
主要发现
| 数据集/模型 | FAD VGG | FAD Trill | FAD MuLan | |
|---|---|---|---|---|
| MusicCaps (Agostinelli et al., 2023) | Riffusion | 13.371 | 0.763 | 0.487 |
| MusicCaps (Agostinelli et al., 2023) | Mubert (MubertAI, 2022) | 9.620 | 0.449 | 0.366 |
| MusicCaps (Agostinelli et al., 2023) | MusicLM (Agostinelli et al., 2023) | 4.0 | 0.44 | - |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Waveform | 2.134 | 0.405 | 0.110 |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Spectrogram | 3.840 | 0.474 | 0.180 |
| AudioSet-Music-Eval | Noise2Music Waveform | 2.240 | 0.252 | 0.193 |
| AudioSet-Music-Eval | Noise2Music Spectrogram | 3.498 | 0.323 | 0.276 |
| MagnaTagATune | Noise2Music Waveform | 3.554 | 0.352 | 0.235 |
| MagnaTagATune | Noise2Music Spectrogram | 5.553 | 0.419 | 0.346 |
- Noise2Music 模型能够生成 reflecting 高层次和细粒度提示属性的 30 秒音频,如风格、节奏、乐器、情感和时代。
- 两阶段级联扩散(用于中间表示的生成器和用于最终音频的级联器)结合超分辨率步骤实现高保真度的 24 kHz 输出。
- 通过 MuLan 和 LaMDA 的大规模伪标签实现对细微语义的支撑,超越标准元数据的限制。
- 在多个数据集上,FAD 分数与 MuLan 相似度显示在质量与语义对齐方面与基线(如 Riffusion 和 Mubert)具有竞争力或更优。
- 人工听感测试表明 Noise2Music 的波形在与 MusicLM 的语义对齐方面与 MusicCaps 提示具有竞争力。
- 通过多词汇伪标签与文本编码(T5)的跨注意力实现对提示的语义与感知保真度的提升。
![Figure 2: We plot how $\text{FAD}_{\text{VGG}}$ and the MuLan similarity score vary as inference parameters are adjusted. The CFG parameters take values from [1, 2, 5, 10, 15], while “B”ack-heavy, “U”niform and “F”ront-heavy denoising step schedules have been applied.](https://ar5iv.labs.arxiv.org/html/2302.03917/assets/figures/ablations.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。