[论文解读] OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching
OAMatcher 是一个无检测器的 Transformer 基网络,专注于可见共现区域以实现密集、精确的局部特征匹配,并具备用于处理嘈杂标签的匹配标签权重策略。
Local feature matching is an essential component in many visual applications. In this work, we propose OAMatcher, a Tranformer-based detector-free method that imitates humans behavior to generate dense and accurate matches. Firstly, OAMatcher predicts overlapping areas to promote effective and clean global context aggregation, with the key insight that humans focus on the overlapping areas instead of the entire images after multiple observations when matching keypoints in image pairs. Technically, we first perform global information integration across all keypoints to imitate the humans behavior of observing the entire images at the beginning of feature matching. Then, we propose Overlapping Areas Prediction Module (OAPM) to capture the keypoints in co-visible regions and conduct feature enhancement among them to simulate that humans transit the focus regions from the entire images to overlapping regions, hence realizeing effective information exchange without the interference coming from the keypoints in non overlapping areas. Besides, since humans tend to leverage probability to determine whether the match labels are correct or not, we propose a Match Labels Weight Strategy (MLWS) to generate the coefficients used to appraise the reliability of the ground-truth match labels, while alleviating the influence of measurement noise coming from the data. Moreover, we integrate depth-wise convolution into Tranformer encoder layers to ensure OAMatcher extracts local and global feature representation concurrently. Comprehensive experiments demonstrate that OAMatcher outperforms the state-of-the-art methods on several benchmarks, while exhibiting excellent robustness to extreme appearance variants. The source code is available at https://github.com/DK-HU/OAMatcher.
研究动机与目标
- 在极端外观变化下推动鲁棒的局部特征匹配,其中检测器会失败。
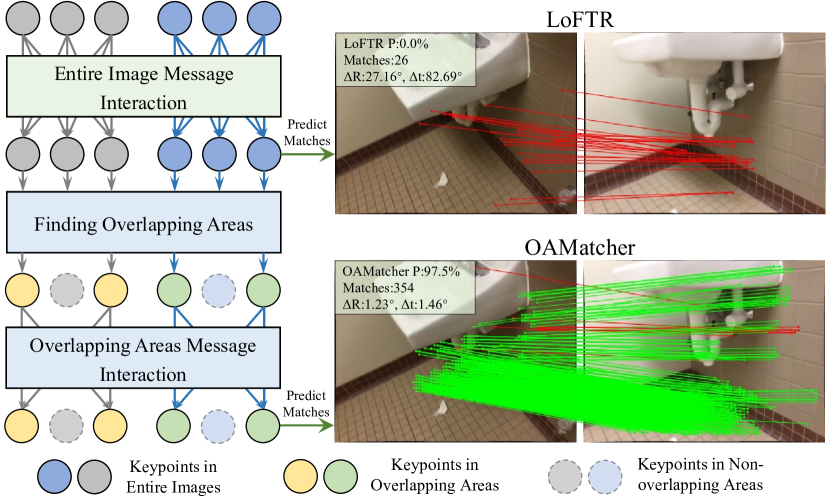
- 引入一种受人类启发的工作流,将焦点从整张图像转移到重叠区域,以实现更清晰的上下文交换。
- 提出对真实标签进行加权的机制,在训练过程中缓解测量噪声。
- 开发一种基于 Transformer 的无检测器架构,整合全局与局部特征以实现密集匹配。
- 在室内和室外基准上展示最先进的性能与鲁棒性。
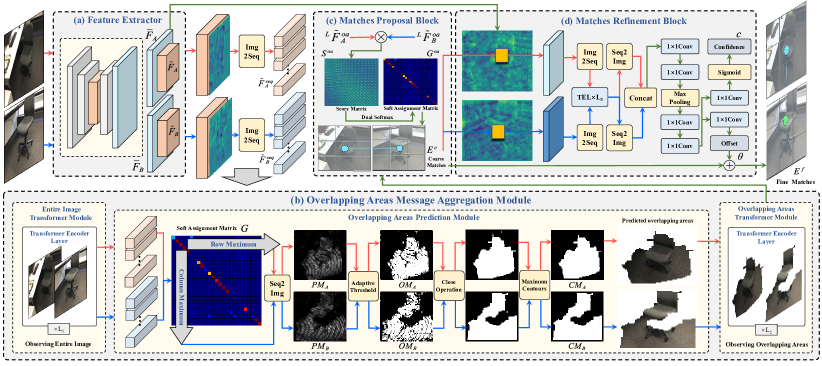
提出的方法
- 跨所有关键点的全局信息整合,以模拟初始的整幅图像观测。
- 重叠区域预测模块(OAPM),通过共可见掩模识别共可见区域。
- 重叠区域 Transformer 模块(OATM),增强重叠区域内的特征。
- 匹配提议块(MPB)与匹配细化块(MRB),用于从粗到精的匹配。
- 匹配标签权重策略(MLWS),为训练分配概率化的标签置信度。
- 将深度卷积集成到 Transformer 编码器层中,以融合局部与全局特征。
实验结果
研究问题
- RQ1预测和利用重叠(共可见)区域是否能提升局部特征匹配在鲁棒性和准确性方面,相对于全图注意力?
- RQ2概率化标签置信度机制(MLWS)是否更善于在训练中处理嘈杂的地面真值匹配?
- RQ3将深度卷积集成到 Transformer 层如何影响用于匹配的局部/全局特征表示?
- RQ4所提出的 OAPM 与 OATM 组件在各基准上是否带来可量化的相较于最先进的无检测方法的提升?
- RQ5相对于基于检测器和无检测器基线,OAMatcher 对极端外观变化是否具备鲁棒性?
主要发现
| 本地特征 | 匹配器 | CCM(ε<1/3/5 px)总览 | 光照 | 视点 |
|---|---|---|---|---|
| D2-Net | NN | 0.38/0.71/0.82 | 0.66/0.95/0.98 | 0.12/0.49/0.67 |
| SuperPoint | NN | 0.46/0.78/0.85 | 0.57/0.92/0.97 | 0.35/0.65/0.74 |
| SuperGlue | - | 0.51/0.82/0.89 | 0.60/0.92/0.98 | 0.42/0.71/0.81 |
| SGMNet | - | 0.52/0.85/0.91 | 0.59/0.94/0.98 | 0.46/0.74/0.84 |
| ClusterGNN | - | 0.52/0.84/0.90 | 0.61/0.93/0.98 | 0.44/0.74/0.81 |
| SparseNCNet | - | 0.36/0.65/0.76 | 0.62/0.92/0.97 | 0.13/0.40/0.58 |
| Patch2Pix | - | 0.50/0.79/0.87 | 0.71/0.95/0.98 | 0.30/0.64/0.76 |
| LoFTR | - | 0.55/0.81/0.86 | 0.74/0.95/0.98 | 0.38/0.69/0.76 |
| MatchFormer | - | 0.55/0.81/0.87 | 0.75/0.95/0.98 | 0.37/0.68/0.78 |
| OAMatcher | - | 0.54/0.85/0.91 | 0.67/0.95/0.98 | 0.42/0.75/0.84 |
- OAMatcher 取得具竞争力的性能并在 3/5 像素阈值下比基线 LoFTR 提升约 4–5 个百分点,见 HPatches 类评估。
- 在 HPatches 上,OAMatcher 报告总体 CCM 为 0.54/0.85/0.91,光照为 0.67/0.95/0.98,视角为 0.42/0.75/0.84。
- OAMatcher 相对于包括无检测同行在内的其他方法,展示了对极端外观变化的鲁棒性。
- 该模型利用自适应阈值和形态学后处理来推导共可见掩模,从而增强对重叠区域的聚焦。
- MLWS 为匹配标签分配概率置信度,减轻嘈杂或不正确的地面真值标签的影响。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。