[论文解读] Offsite-Tuning: Transfer Learning without Full Model
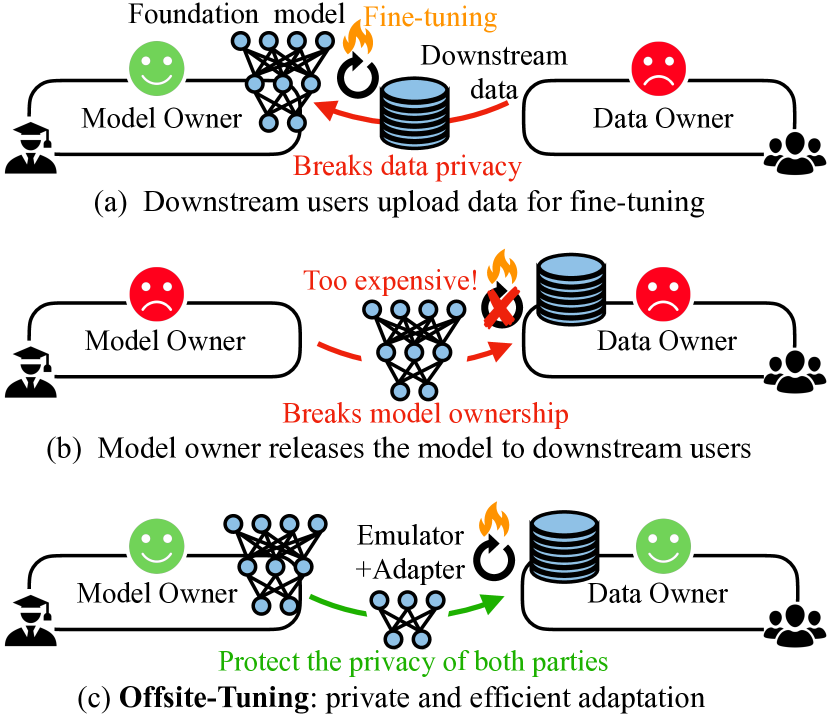
Offsite-Tuning 使在无需获取完整模型权重的情况下,将十亿参数的基础模型调整到下游数据,使用一个可训练的适配器和与数据所有者共享的有损压缩的仿真器(emulator),实现隐私保护且更高效的微调,且性能与完整微调相当。
Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at https://github.com/mit-han-lab/offsite-tuning.
研究动机与目标
- 在微调专有基础模型以完成下游任务时,强调隐私和效率挑战。
- 提出一个在不暴露完整模型权重或数据的情况下进行微调的框架。
- demonstrated applicability to both language and vision foundation models across standard benchmarks.
提出的方法
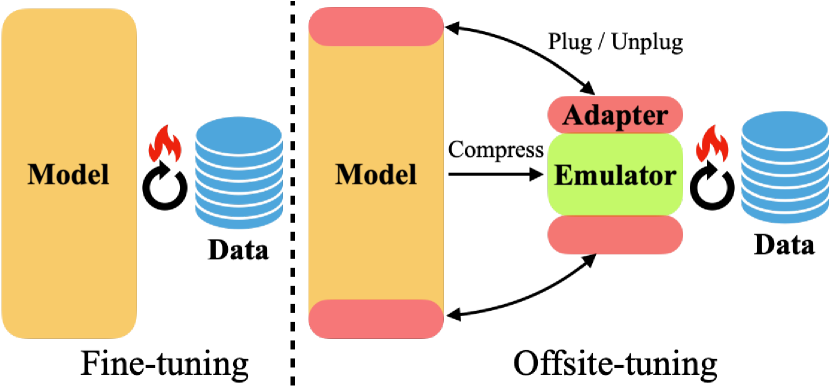
- 将基础模型拆分为一个小型可训练适配器 (A) 和一个冻结的剩余部分 (E);对 E 进行有损压缩以创建一个仿真器 (E*)。
- 在数据所有者那里提供 [A, E*],数据所有者使用来自 E* 的近似梯度对 A 进行微调。
- 将更新后的适配器 A' 返回给模型所有者,后者将其注入到完整模型以产生 M' = [A', E]。
- 通过丢弃 E 的中间层来实现基于层丢弃的仿真器压缩,同时保留前后两层;在资源允许时可从 E 中蒸馏出 E*。
- 将适配器设计为一个三明治 M = A1 ∘ E ∘ A2,以同时捕捉浅层与深层的更新,相比仅更新顶部或底部层,提升转移性能。
- 将 Offsite-Tuning 与参数高效微调技术(Adapter、LoRA、BitFit)结合,在适配器层应用这些方法以进一步减少可训练参数。
实验结果
研究问题
- RQ1小型适配器加压缩仿真器是否能在不分享完整模型权重或数据的前提下,实现对十亿参数基础模型的有效微调?
- RQ2仿真器应如何压缩以在对适配器有用的梯度和对模型所有权的保护之间取得平衡?
- RQ3插件式(在数据所有者数据上训练的适配器,然后插入到完整模型中)方法在语言和视觉任务上是否能接近完全微调的性能?
- RQ4使用 Offsite-Tuning 时的效率提升(吞吐量、内存)有多大,并且如何随模型规模和压缩策略扩展?
- RQ5Offsite-Tuning 如何与现有的参数高效微调方法交互?
主要发现
- Offsite-Tuning 在若干语言和视觉任务上实现了与完全微调相当的插件式性能,同时保持隐私(不可访问完整模型权重)。
- 基于层丢弃的仿真器压缩在性能和隐私之间提供了最佳平衡,仿真器与插件式性能之间存在可观的差距,但能保护模型所有权。
- 对仿真器进行蒸馏进一步提升插件式性能,相较于仿真器性能在特定模型(如 OPT-1.3B 和 GPT2-XL)上改善结果。
- 将 Offsite-Tuning 与参数高效微调方法(Adapter、LoRA)结合时,在保持或提升插件式性能的同时降低可训练参数;BitFit 在某些情况下往往不如完全微调。
- 效率提升显著:在单 GPU 硬件上与 LoRA 结合时,吞吐量最高可提升 6.5x、内存降低 5.6x。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。