[论文解读] On Leveraging Large Language Models for Enhancing Entity Resolution: A Cost-efficient Approach
该论文提出了一种基于大语言模型的、面向成本的实体解析框架,选择一组最优的匹配问题(MQsSP)以在给定预算内降低不确定性(熵),并使用LLM置信度来调整分区概率。
Entity resolution, the task of identifying and merging records that refer to the same real-world entity, is crucial in sectors like e-commerce, healthcare, and law enforcement. Large Language Models (LLMs) introduce an innovative approach to this task, capitalizing on their advanced linguistic capabilities and a ``pay-as-you-go'' model that provides significant advantages to those without extensive data science expertise. However, current LLMs are costly due to per-API request billing. Existing methods often either lack quality or become prohibitively expensive at scale. To address these problems, we propose an uncertainty reduction framework using LLMs to improve entity resolution results. We first initialize possible partitions of the entity cluster, refer to the same entity, and define the uncertainty of the result. Then, we reduce the uncertainty by selecting a few valuable matching questions for LLM verification. Upon receiving the answers, we update the probability distribution of the possible partitions. To further reduce costs, we design an efficient algorithm to judiciously select the most valuable matching pairs to query. Additionally, we create error-tolerant techniques to handle LLM mistakes and a dynamic adjustment method to reach truly correct partitions. Experimental results show that our method is efficient and effective, offering promising applications in real-world tasks.
研究动机与目标
- 在数据丰富的领域中,推动使用大语言模型(LLMs)来改善实体解析。
- 引入一个兼顾准确性和LLM使用成本的成本感知工作流。
- 定义并解决匹配问题选择问题(MQsSP),在预算约束下最小化不确定性。
- 建模LLM响应如何调整分区概率并降低结果集中的熵。
提出的方法
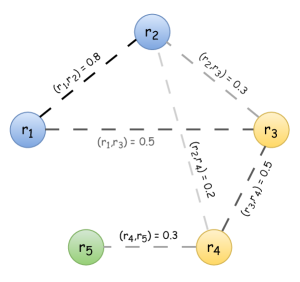
- 将记录表示为图中的节点,并定义带有相关概率的记录聚类的可能分区。
- 使用香农熵来量化分区结果集(RS)中的不确定性。
- 定义匹配问题(MQ)及成本函数 F(MQ),以捕捉LLM定价,从而实现预算约束的 MQ 选择。
- 将 MQsSP 形式化为在类似背包的预算约束下最大化联合熵减少,并提出具备 (1-1/e) 保证的贪心、子模优化方法。
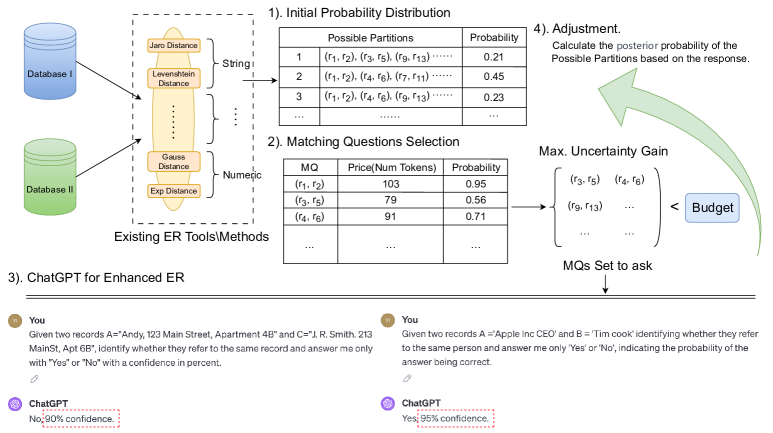
- 开发一个基于LLM辅助的实体解析工作流(算法2),迭代选择 MQs、向LLM查询并更新分区概率。
- 提供一个概率调整模型(包含 Cap 与 Conf),在更新 RS 时考虑LLM不完美响应的影响。
实验结果
研究问题
- RQ1如何将LLMs作为服务来在控制成本的同时改进实体解析?
- RQ2在预算约束下,选择一组能够最大化减少不确定性的匹配问题的有效方法是什么?
- RQ3如何整合LLM的响应以完善对可能分区的概率分布?
- RQ4MQsSP 的计算复杂性是什么,是否可以在实际中高效地近似?
主要发现
- MQsSP 即使在 k=1 的特殊情形下也是 NP-hard(可化为 0/1 背包问题)。
- 使用子模性的一种贪心近似法给出一个在预算约束下有效的 MQ 选择策略,具有 (1-1/e) 的性能保证。
- 基于熵的框架允许在纳入LLM响应时量化不确定性降低。
- 该框架通过基于LLM回答及置信度调整分区分布,在实体解析中实现成本效益高的不确定性降低。
- 在数据集(ACM、Amazon-eBay、Electronics)上的实验表明,该方法在预算内可降低不确定性,同时使用已建立的ER工具进行初步分区。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。