[论文解读] On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
本论文实证评估 OpenAI 的 o1 模型在规划任务上的表现,分析在多个基准上的可行性、最优性和泛化性,并将其与 GPT-4 进行比较。
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $ extit{Barman}$, $ extit{Tyreworld}$) and spatially complex environments (e.g., $ extit{Termes}$, $ extit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning. Code available at https://github.com/VITA-Group/o1-planning.
研究动机与目标
- 评估 o1 模型在领域约束下生成可行计划的能力。
- 评估 o1 模型生成计划的最优性,关注行动效率与冗余。
- 考察 o1 模型对未见任务或符号化表示任务的泛化能力。
- 识别在记忆/决策中的常见规划错误和瓶颈。
- 提供通过自我评估与记忆技巧改进基于LLM的规划的方向。
提出的方法
- 在 GPT-4、o1-mini 和 o1-preview 下对一组规划任务(Barman、Blocksworld、Floortile、Grippers、Tyreworld、Termes)进行基准测试。
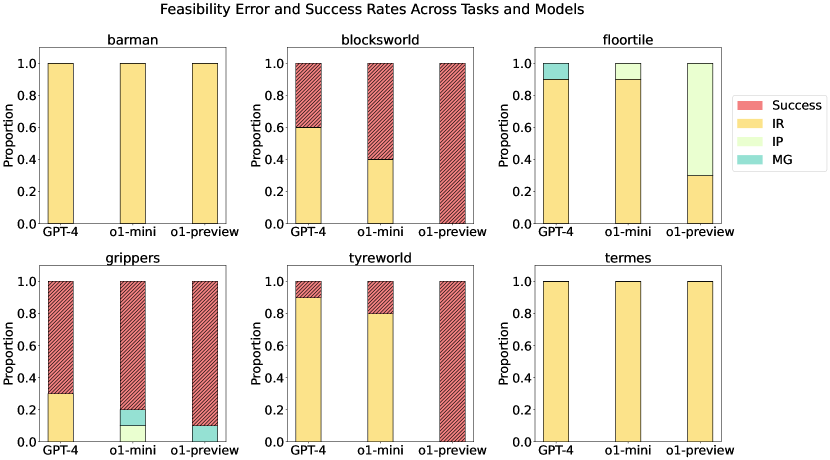
- 将错误分类为可行性(IR、IP、MG)和最优性(LO);测量成功率、可行性和最优性率。
- 分析在空间和动作复杂度上的性能,以识别瓶颈。
- 在 o1-preview 中利用自我评估机制在规划过程中评估并纠正行动。
- 通过使用抽象/符号化任务表示(随机 Tyreworld)进行测试来比较泛化。
- 突出局限性并提出在内存管理、约束遵循和泛化方面的未来方向。
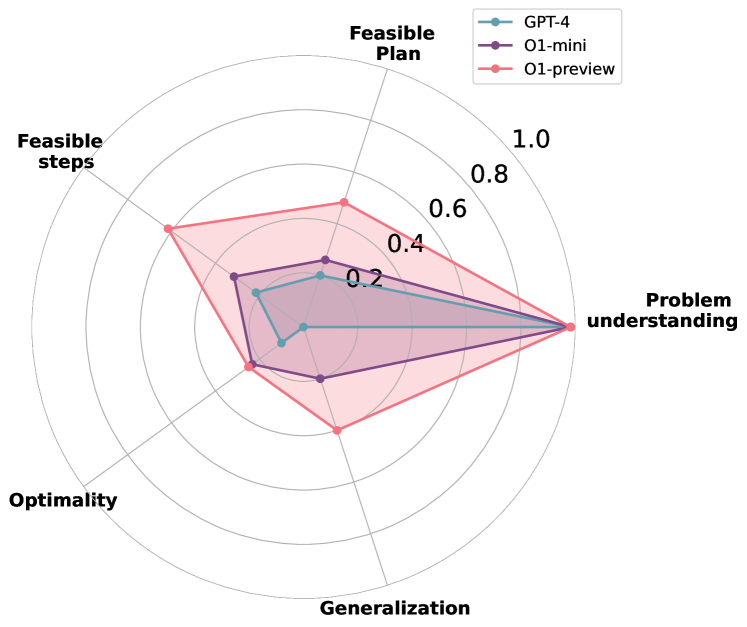
实验结果
研究问题
- RQ1在多样化的规划领域中,o1 模型生成的计划的可行性如何?
- RQ2o1 模型是否产出比 GPT-4 更优(更高效)的计划,在哪些方面仍然不足?
- RQ3o1 模型能否将规划策略泛化到抽象或符号化表示的任务?
- RQ4在 o1 模型中观察到的主要规划错误类型(IR、IP、MG、LO)有哪些,按领域如何变化?
- RQ5影响规划 performance 的内存、状态管理和空间推理的关键瓶颈是什么?
主要发现
- o1-preview 在多个领域通常比 GPT-4 和 o1-mini 获得更高的成功率,在某些情况下对 Blocksworld 和 Tyreworld 测试集达到完全成功。
- o1-preview 提高了对约束的遵循和自我评估,但在如 Termes 这样的复杂空间中仍存在非最优计划(LO)和误解(MG)。
- GPT-4 在遵循约束和规划效率方面经常表现不佳,尤其是在更具空间复杂性的任务中。
- Floortile 在所有模型中普遍失败,IR 错误在 GPT-4 和 o1-mini 中占主导,而 o1-preview 虽降低了 IR 的发生,但仍面临其他错误。
- Grippers 任务中 o1-preview 取得高达 90% 的成功率和 70% 的最优性,在许多情况下优于 GPT-4 和 o1-mini。
- 泛化测试显示 o1-preview 在结构化泛化(Grippers)方面比 GPT-4 更强,但在抽象符号表示(随机 Tyreworld)时性能下降。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。