[论文解读] On the Variance of Neural Network Training with respect to Test Sets and Distributions
本文认为独立训练运行之间的测试集方差在很大程度上来自有限样本噪声和初始条件敏感性;而在收敛后,按分布的方差较小;集成校准意味着不可避免但有界的测试集方差。
Typical neural network trainings have substantial variance in test-set performance between repeated runs, impeding hyperparameter comparison and training reproducibility. In this work we present the following results towards understanding this variation. (1) Despite having significant variance on their test-sets, we demonstrate that standard CIFAR-10 and ImageNet trainings have little variance in performance on the underlying test-distributions from which their test-sets are sampled. (2) We show that these trainings make approximately independent errors on their test-sets. That is, the event that a trained network makes an error on one particular example does not affect its chances of making errors on other examples, relative to their average rates over repeated runs of training with the same hyperparameters. (3) We prove that the variance of neural network trainings on their test-sets is a downstream consequence of the class-calibration property discovered by Jiang et al. (2021). Our analysis yields a simple formula which accurately predicts variance for the binary classification case. (4) We conduct preliminary studies of data augmentation, learning rate, finetuning instability and distribution-shift through the lens of variance between runs.
研究动机与目标
- 研究独立训练运行之间测试集准确率方差的原因。
- 判断在测试集上表现最好的运行是否在测试分布上具有高于平均水平的泛化。
- 识别哪些超参数或训练方面会影响方差。
- 建立一个统计框架,将测试集方差与分布-wise 方差和集成校准联系起来。
提出的方法
- 在 CIFAR-10 和 ImageNet 上进行大约 35 万个网络的实证训练以表征方差。
- 控制随机性来源(模型初始化、数据顺序、增强等)以隔离其影响。
- 提出假设1(样本级独立性)来建模测试准确率分布。
- 推导分布-wise 方差的无偏估计量(方程2)。
- 在理论上将测试集方差与通过定理3–5得到的集成校准联系起来。
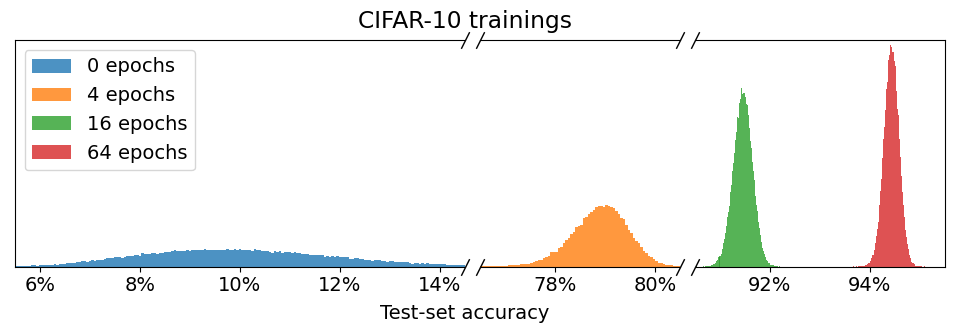
实验结果
研究问题
- RQ1是什么原因导致独立训练运行之间的方差,最主要的随机性来源是什么?
- RQ2在测试集上选择最佳运行是否意味着对测试分布的高于平均泛化?
- RQ3哪些超参数会影响测试集方差和分布-wise 方差?
- RQ4我们是否可以从有限的测试样本中估计分布-wise 方差,并将其与集成校准联系起来?
- RQ5在分布转移、数据增强和学习率改变下,方差的行为如何?
主要发现
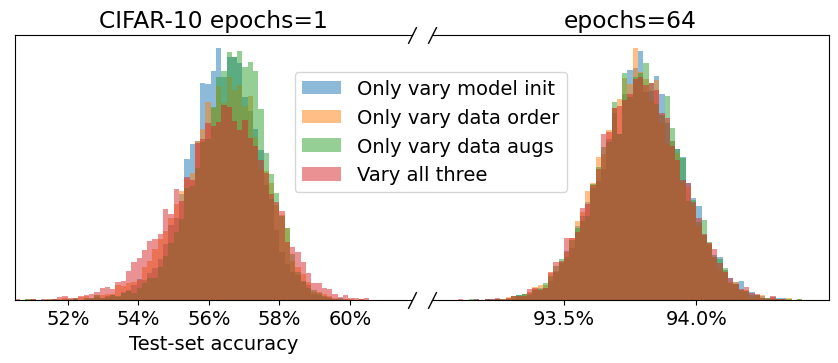
- 运行之间的方差在很大程度上源于对初始条件的极端敏感性,而非任意单一随机来源。
- 随着训练收敛,独立测试集分割的相关性降低,表明分布-wise 准确率中真正的方差有限。
- 一个无偏估计量表明分布-wise 方差在收敛后在 CIFAR-10 约为 0.033%、在 ImageNet 约为 0.034%(极小的分布方差)。
- 集成校准意味着分类任务的不同运行之间存在正向的测试集方差。
- BERT-Large 微调的分布-wise 方差明显高于 BERT-Base,表明模型大小影响不稳定性。
- 分布转移的测试集显示的方差比同域集更大,数据增强可以降低方差。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。