[论文解读] One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
一种前馈方法将单张图像在约 45 秒内转换为完整的 360° 纹理化 3D 网格,通过将一个视图条件的 2D 扩散模型与可泛化的基于 SDF 的重建相结合,避免对每个形状进行优化。
Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
研究动机与目标
- 激发一种通用的单图像到 3D 重建的解决方案,能够覆盖不同对象类别。
- 利用强大的 2D 扩散先验来为 3D 提升生成多视图预测。
- 开发一个 360° 网格重建流水线,具备前馈性且无需优化。
- 在紧贴输入图像的同时,确保几何质量和 3D 一致性得到提升。
提出的方法
- 使用一个视图条件的 2D 扩散模型(Zero123)从单张输入图像生成多视图图像。
- 估计输入视图的仰角并为多视图集合构建相机位姿。
- 应用基于代价体积、可泛化的神经表面重建(SparseNeuS),以单次传递生成带纹理的 3D 网格。
- 采用两阶段源视图选择和地面真值-预测混合监督进行训练,以处理不一致的多视图预测。
- 引入仰角估计模块,使 Zero123 的视角与重建坐标系对齐。
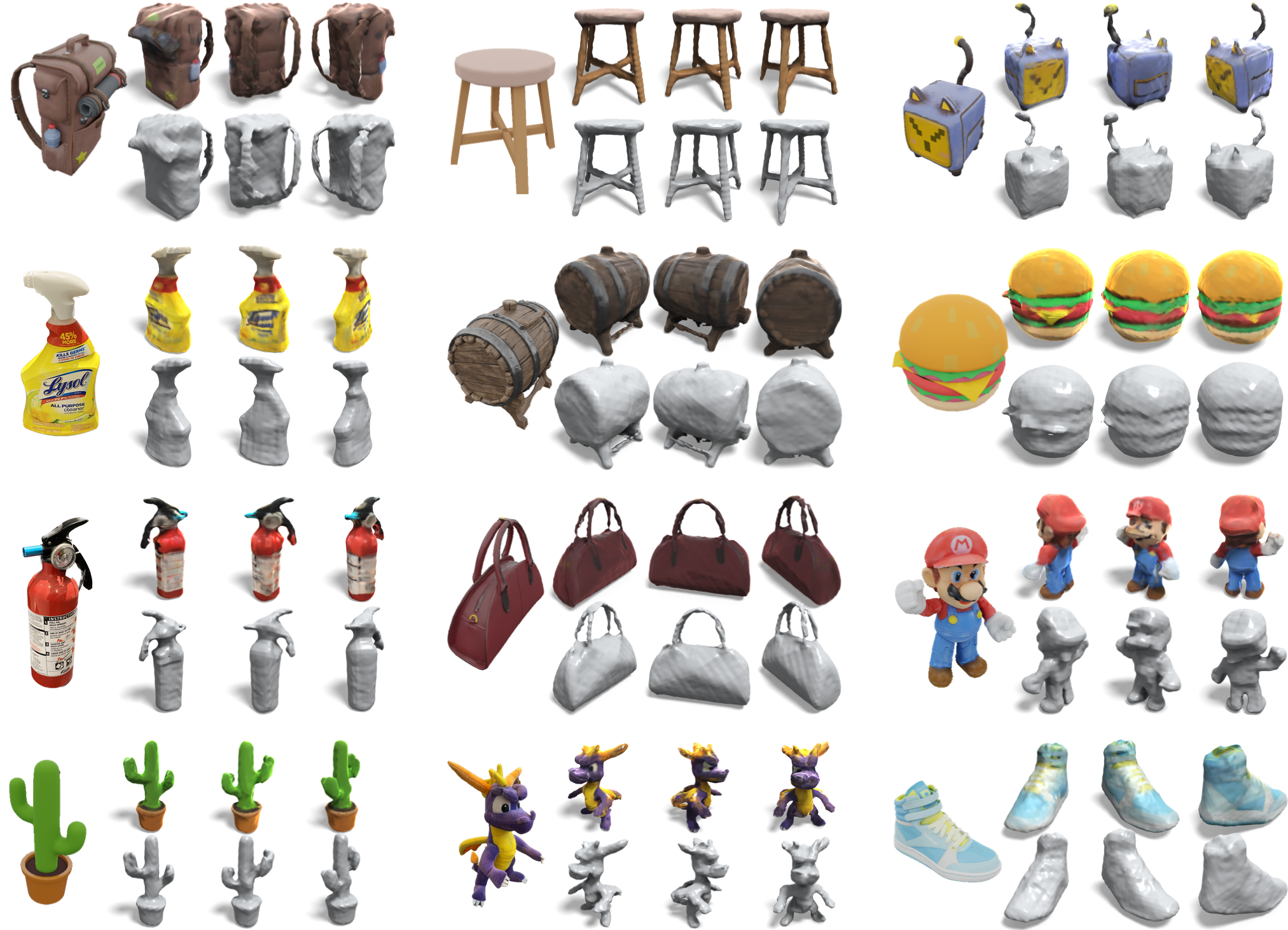
实验结果
研究问题
- RQ1是否可以在不对每个形状进行优化的情况下,将单张图像提升为高质量、带纹理的 360° 网格?
- RQ2如何有效利用 2D 扩散先验,在未见到的对象类别上实现稳健的 3D 重建?
- RQ3需要哪些训练策略和位姿估计机制,才能把不完美的多视图预测与单次前向传播重建协调一致?
主要发现
- 该方法在约 45 秒内从单张图像重建一个完整的 360° 纹理网格,且无需对每个形状进行优化。
- 使用带有两阶段视图选择和深度监督的 SparseNeuS,在预测视图上的 360° 几何和 3D 一致性方面优于对预测视图进行的 NeRF/SDF 优化。
- 仰角估计足够准确,能够实现一致的相机位姿,对正确的 3D 重建至关重要。
- 相较于有竞争力的零-shot 和基于优化的基线,该方法在几何保真度和对输入图像的贴合度上具有优势,同时保持具有竞争力的运行时。
- 该框架可以通过与现成的 2D 文本到图像扩散模型整合,扩展为文本到 3D。
![Figure 2: Our method consists of three primary components: (a) Multi-view synthesis : we use a view-conditioned 2D diffusion model, Zero123 [ 36 ] , to generate multi-view images in a two-stage manner. The input of Zero123 includes a single image and a relative camera transformation, which is parame](https://ar5iv.labs.arxiv.org/html/2306.16928/assets/figures/pipeline.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。