[论文解读] One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
One-2-3-45++ 将单张图像在大约一分钟内转换为高保真、带纹理的3D网格,方法是(1)通过微调的2D扩散生成一致的多视图图像;(2)使用多视图条件化3D扩散对其进行提升并进行轻量纹理细化。
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
研究动机与目标
- 利用2D扩散先验和有限的3D数据从单张图像生成高保真3D资产。
- 确保一致的多视图图像生成以改进后续3D重建。
- 使用多视图条件化3D扩散模型将多视图提升到3D并高效地细化纹理。
提出的方法
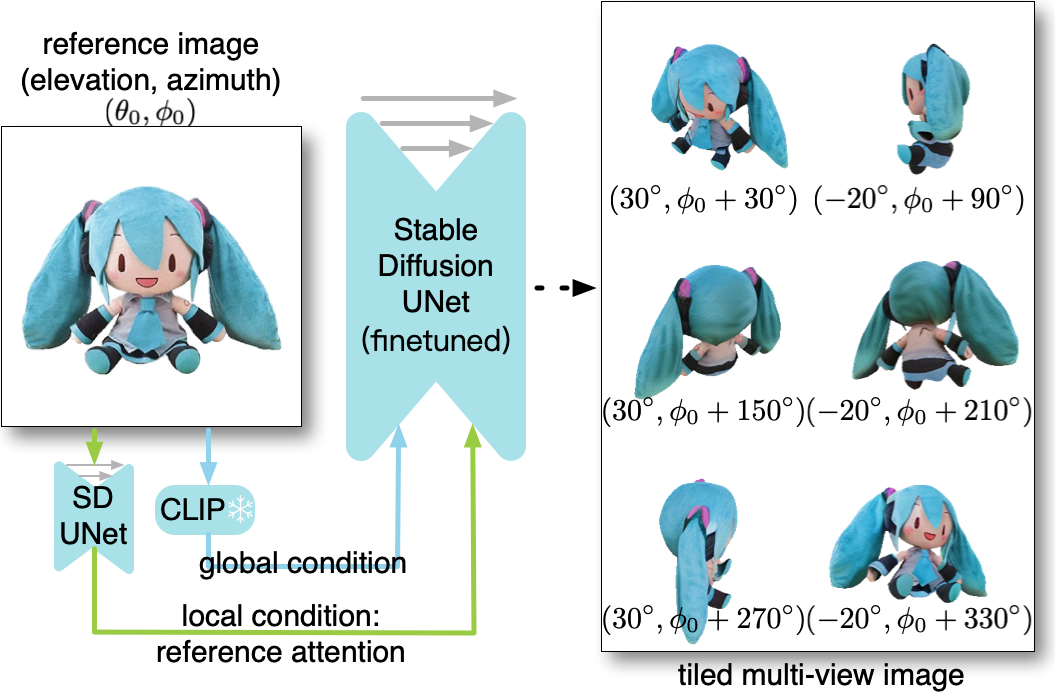
- 将六个视图拼接成单张图像并微调2D扩散模型,以生成以输入图像为条件的一致多视图复合图像。
- 使用多视图条件化3D扩散_MODEL_以粗到细的双阶段过程重建带纹理的3D网格(占据/体积,然后高分辨率SDF+颜色)。
- 从多视图局部图像特征构建3D特征体并用已知相机姿态投影,引导3D扩散。
- 结合基于CLIP的全局条件和局部多视图条件体进行3D扩散,输出包含占据和颜色的结果。
- 通过使用一致的多视图图像作为监督,优化颜色场(TensorField风格)实现轻量纹理细化步骤。
- 在Objaverse/Objaverse派生渲染并进行数据增强与随机姿态扰动的训练;推理时通过去噪64^3占据体积再进行高分辨率稀疏体积扩散及 marching cubes。

实验结果
研究问题
- RQ1一致的多视图生成能否提高从单张图像进行的3D重建质量?
- RQ2与先前的基于NeRF或扩散的方法相比,基于多视图条件的3D扩散模型是否能产生更高质量的带纹理网格?
- RQ3所提出的两阶段3D扩散加轻量纹理细化在保留与输入图像的保真度的同时是否更快?
- RQ4在3D扩散中,多视图局部条件与全局条件相比,在3D IoU、F-score和CLIP相似度方面有何差异?
主要发现
| 方法 | F-Sco. (%) | CLIP-Sim | 用户偏好 | 耗时 |
|---|---|---|---|---|
| Zero123 XL [10] | 91.6 | 73.1 | 58.6 | 30min |
| One-2-3-45 [34] | 90.4 | 70.8 | 52.7 | 45s |
| SyncDreamer [37] | 84.8 | 68.9 | 28.4 | 6min |
| DreamGaussian [63] | 81.0 | 68.4 | 31.5 | 2min |
| Shap-E [25] | 91.8 | 73.1 | 40.8 | 27s |
| Ours | 93.6 | 81.0 | 87.6 | 60s |
- 在GSO数据集的单张图像到3D任务上,在F-Score、CLIP相似度和用户偏好方面超越基线(例如,One-2-3-45++ 达到 93.6 F-Score、81.0 CLIP-Sim、87.6 User-Pref、60s)。
- 在运行时间上优于基于优化的方法(≤1分钟),同时保持或提升对输入视图的保真度。
- 消融实验显示一致的多视图生成和多视图条件化3D扩散是关键;移除它们会降低3D IoU和CLIP相似度。
- 结合多视图监督的纹理细化提升纹理质量和CLIP相似度。
- 相比文本到3D基线,One-2-3-45++在CLIP相似度和用户偏好上更高,且运行时间显著更快(60s vs 几小时)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。