[论文解读] Open-Source LLMs for Text Annotation: A Practical Guide for Model Setting and Fine-Tuning
本研究在11项文本标注任务中比较开源大型语言模型(HuggingChat、FLAN)与 ChatGPT 及 MTurk 的表现,探索零-shot 与少量-shot 设置下的不同温度参数,发现开源LLM在多数任务上优于 MTurk,且在某些任务接近 ChatGPT。
This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
研究动机与目标
- 评估开源LLM(HuggingChat、FLAN)相对于 ChatGPT 与 MTurk 在多项文本标注任务中的表现。
- 研究在不同温度设置下的零-shot 与少量-shot 学习。
- 考察模型大小与提示对标注准确性与编码者间一致性的影响。
- 评估开源LLM在成本、数据保护和可重复性方面的实际表现。
- 为文本标注任务的模型设置选择提供指南。
提出的方法
- 在4个数据集上对11项标注任务比较 ChatGPT、HuggingChat 与 FLAN。
- 在零-shot下测试 ChatGPT 与 HuggingChat,并在多种温度设置下测试;FLAN 在零-shot 下以 L/XL/XXL 尺度进行测试。
- 每个设置进行两次运行以计算编码者间一致性。
- 使用带 Chain-of-Thought (CoT) 的少-shot 提示,提供每个类别的两个人类标注示例。
- 在培训标注员和 MTurk 作为金标准的基础上衡量准确性。
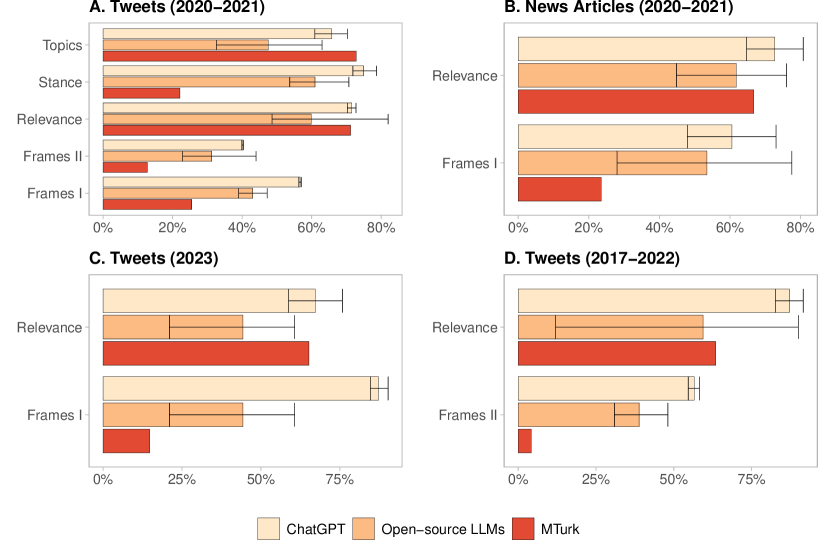
实验结果
研究问题
- RQ1开源LLM 是否在文本标注任务中胜过众包工人并接近 ChatGPT?
- RQ2零-shot 与少量-shot 提示以及温度设置如何影响跨任务的性能?
- RQ3与专有模型和 MTurk 相比,使用开源LLM 进行标注的成本与数据保护影响如何?
- RQ4模型输出与人类标注者的一致性如何,通过编码者间一致性来衡量?
主要发现
- ChatGPT 通常在所有任务中取得最高的平均准确度。
- 开源LLM 在多数任务中优于 MTurk,对于表现最好的模型,在某些任务上甚至可超过 ChatGPT。
- 表现出色的开源LLM 在十一项任务中的九项胜过 MTurk,在若干任务上接近 ChatGPT。
- 性能因数据集和任务而异;没有一个设置对所有模型都普适地最大化性能。
- 较低的温度设置通常提升 HuggingChat 的表现,而 FLAN 的更大规模并不保证更好(FLAN 仅在零-shot 下测试)。
- 开源LLM 在成本方面具有显著优势(使用免费)并在数据保护方面更严谨(不进行第三方数据共享)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。