[论文解读] OpenAssistant Conversations -- Democratizing Large Language Model Alignment
本论文发布 OpenAssistant Conversations,这是一个大型的多语言、由人类生成的数据集,用于对齐大语言模型,并通过在开源架构上训练和评估 SFT、RM 和 RLHF 模型来展示其有用性。
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models. We release our code and data under a fully permissive licence.
研究动机与目标
- 通过发布一个大型、开放的数据集,民主化获取用于 LLM 对齐的高质量人类反馈数据。
- 评估数据集的安全性、伦理和审核含义。
- 通过在开放架构上训练和评估 SFT、奖励模型(RM)和基于 RLHF 的模型,展示数据集的实用性。
提出的方法
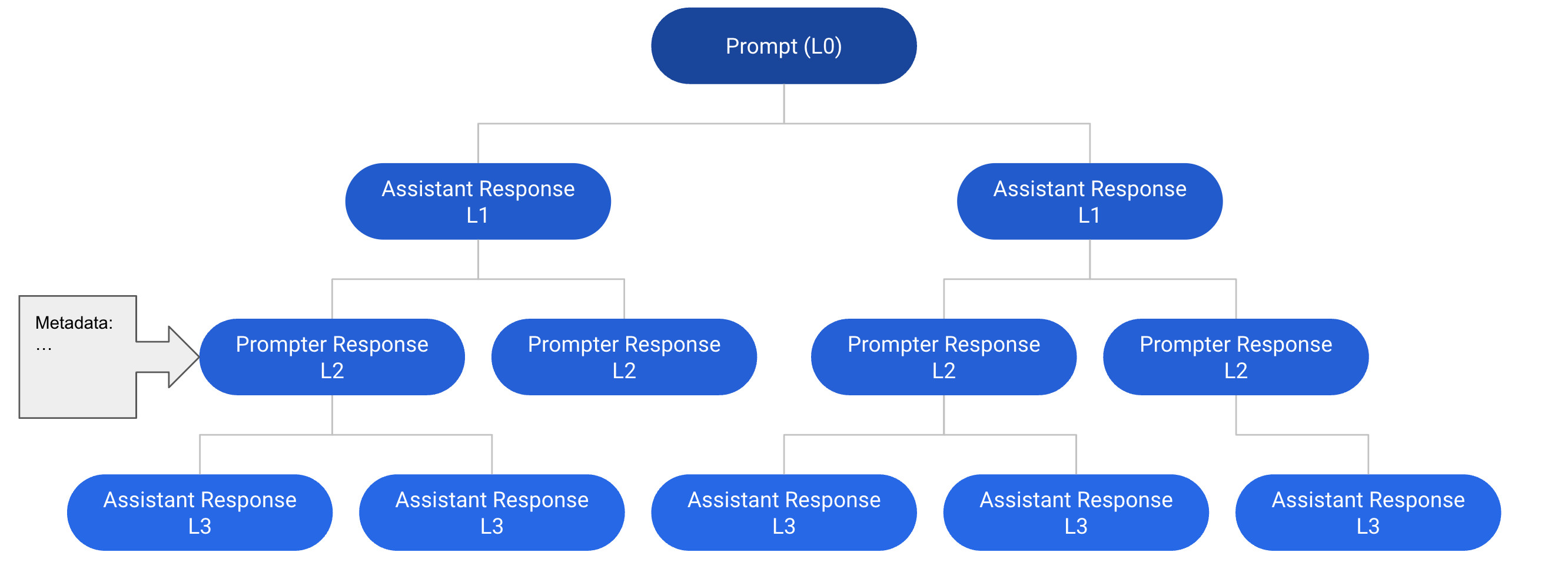
- 发布包含 161,443 条信息、66,497 棵树、35 种语言、以及 461,292 份高质量评价的 OpenAssistant Conversations 数据集。
- 通过众包方式收集数据,包含五种任务类型:提示、以助手身份回复、以提示者身份回复、标注和排序。
- 树状态机管理对话树的创建、增长与完成;通过奖励、排行榜和人工评审进行审核与质量控制。
- 在开源模型如 Pythia、Falcon 和 LLaMA 上训练 SFT 模型、奖励模型(RM)和 RLHF 模型;在标准基准上进行评估。
- 与基线的对比表明,OpenAssistant Conversations 赋能的模型在若干基准上优于部分基线对手。
实验结果
研究问题
- RQ1一个开放、由人类注释的大型对话数据集是否能推动对齐相关微调的改进?
- RQ2用 OpenAssistant Conversations 训练的 SFT、RM 和 RLHF 模型在标准 NLP 基准上的表现相较基线如何?
- RQ3此类数据集的安全性、毒性和审核特征是什么,自动化毒性测量与人类判断的一致性如何?
- RQ4由志愿者驱动的开放数据集收集过程会带来哪些偏见或局限性,这些如何影响模型行为?
- RQ5如何释放数据和模型以最大化可重复性和负责任的研究?
主要发现
- OpenAssistant Conversations 包含 161,443 条信息(其中 91,829 条为提示者;69,614 条为助手)分布于 66,497 棵树,覆盖 35 种语言,且有 461,292 份高质量评价。
- 使用该数据训练的模型在标准基准上相对于各自的基础模型表现出一致的改进。
- 与 SFT 相比,RLHF 在某些基准上有提升,但并非对所有任务都一致,显示出数据集与评估的细节差异。
- 自动化毒性测量(Detoxify)在某种程度上与人类标签相关,审核机制显著降低了毒性内容,尽管出于其他原因仍可能删除非毒性信息。
- 数据集与模型采用宽松的许可条款发布,支持开放研究,同时认识到偏见与安全性方面的考量。
- 用户研究和人口统计分析揭示了参与者在某些维度上的同质性,以及由于参与不均衡带来的潜在偏差。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。