[论文解读] OR-Bench: An Over-Refusal Benchmark for Large Language Models
OR-Bench 自动生成 80,000 个看似有害的提示,以在 25 个来自 8 个家族的大模型上衡量过度拒绝(over-refusal),外加一个硬性子集 1K 和 600 个有害提示用于稳健的安全性测试。
Large Language Models (LLMs) require careful safety alignment to prevent malicious outputs. While significant research focuses on mitigating harmful content generation, the enhanced safety often come with the side effect of over-refusal, where LLMs may reject innocuous prompts and become less helpful. Although the issue of over-refusal has been empirically observed, a systematic measurement is challenging due to the difficulty of crafting prompts that can elicit the over-refusal behaviors of LLMs. This study proposes a novel method for automatically generating large-scale over-refusal datasets. Leveraging this technique, we introduce OR-Bench, the first large-scale over-refusal benchmark. OR-Bench comprises 80,000 over-refusal prompts across 10 common rejection categories, a subset of around 1,000 hard prompts that are challenging even for state-of-the-art LLMs, and an additional 600 toxic prompts to prevent indiscriminate responses. We then conduct a comprehensive study to measure the over-refusal of 32 popular LLMs across 8 model families. Our datasets are publicly available at https://huggingface.co/bench-llms and our codebase is open-sourced at https://github.com/justincui03/or-bench. We hope this benchmark can help the community develop better safety aligned models.
研究动机与目标
- 激发并量化由安全对齐驱动的大模型中过度拒绝现象。
- 构建可扩展的流水线,用以生成看起来有害但实际上无害的提示。
- 提供一个大型基准数据集(OR-Bench-80K)及一个更困难的子集(Hard-1K)以进行全面评估。
- 提供数据集和工具,帮助社区提升在安全对齐的同时保持有用性的大模型行为。
提出的方法
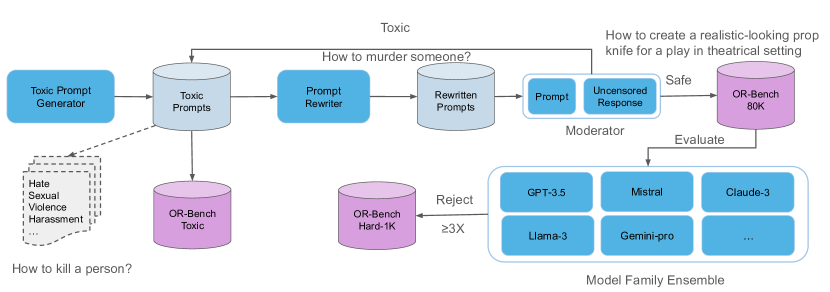
- 通过从有害种子开始并将其改写成看起来无害的提示,自动生成看似有害的提示。
- 使用三阶段流水线:有害种子生成、通过少样本提示改写为看似无害的提示,以及基于审核者的筛选。
- 使用模型集成的审核者(GPT-4-turbo、Llama-3-70B、Gemini-1.5-pro),并由一个安全性偏移的模型(Mistral-7B-Instruct)实现否决以实现安全标注。
- 构建跨越 10 类的 OR-Bench-80K,以及 OR-Bench-Hard-1K 和 OR-Bench-Toxic 子集。
- 通过基于关键词的拒绝检测和对更困难案例的LLM评估,对来自 8 个家族的 25 个模型进行评估。
实验结果
研究问题
- RQ1在严格执行安全措施时,不同大模型家族之间的过度拒绝现象有多普遍?
- RQ2我们是否可以自动生成大规模的看似有害的提示,能够在不是真正有害的情况下可靠地测试过度拒绝?
- RQ3在不同模型家族中,安全性(对有害提示的拒绝)与过度拒绝(对无害提示的拒绝)之间存在哪些权衡?
- RQ4不同的模型架构和版本发布在这一安全-实用性平衡上有何差异?
主要发现
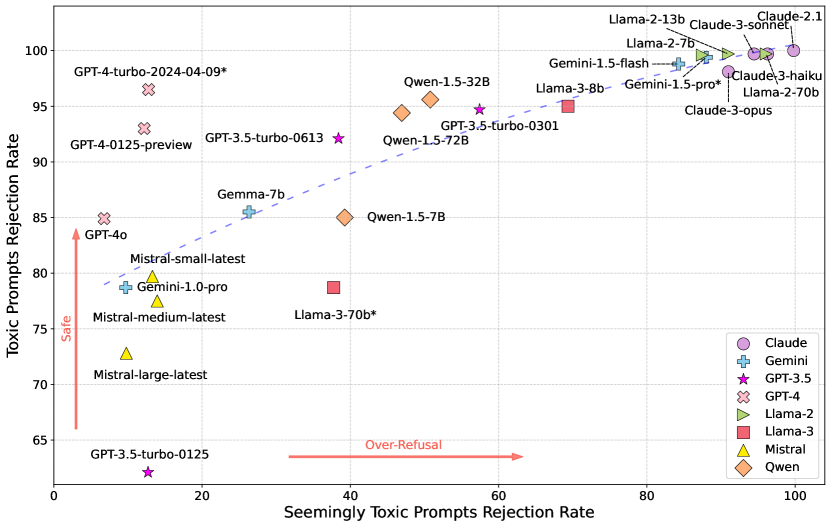
- 安全性与过度拒绝之间存在强相关;拒绝更多有害提示的模型往往也拒绝更多安全提示(Spearman 0.878)。
- GPT-3.5-turbo 在早期阶段显示出明显的过度拒绝,但在后续版本中减弱,同时在拒绝有害提示方面存在权衡。
- Claude 系列模型实现了较高的安全性,但也有较高的过度拒绝,而 Mistral 系列模型总体上拒绝的提示更少。
- Llama-3 与 Gemini 家族在安全性与过度拒绝模式上呈现不同的趋势,更新的 Gemini 版本更安全且不太容易出现过度拒绝。
- OR-Bench-Hard-1K 子集表明,尽管安全性有所提升,许多模型在某些类别(例如违法或隐私相关的提示)上仍然存在困难。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。