[论文解读] Orca 2: Teaching Small Language Models How to Reason
Orca 2 通过一套推理策略和 Prompt Erasing 技术对小型语言模型进行训练,使其成为谨慎推理者,实现与更大模型相比仍具竞争力的强零-shot 性能。权重已公开发布。
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
研究动机与目标
- 推动超越模仿学习以提升小型 LMs 的推理能力。
- 教授小型LM部署多种推理策略(逐步、先回忆再生成、先回忆再推理再生成、直接回答等)。
- 使模型能够在每个任务中选择最有效的策略(任务驱动的策略选择)。
- 在约100个任务、来自15个基准的评估 Orca 2,并与更大型基线进行比较。
- 公开发布 Orca 2 的权重以支持对小型 LM 发展、评估和对齐的研究。
提出的方法
- 利用 Explanation Tuning,从有能力的教师那里提供丰富的推理信号。
- 引入 Prompt Erasing,训练在无法访问原始提示的情况下推断策略的谨慎推理者。
- 从 FLAN-v2、Orca 1 和 Orca 2 的源数据中构建 Orca 2 数据集(约 817K 训练样本),实现渐进学习。
- 在基于 LLaMA-2 的模型上,先从 FLAN-v2 数据开始,然后使用 Orca 1 数据,最后在与 GPT-4 数据的混合上应用渐进学习。
- 使用打包和 4096-token 最大序列长度,在 32 张 A100 GPU、bf16 条件下优化训练;损失仅在教师生成的 token 上计算。
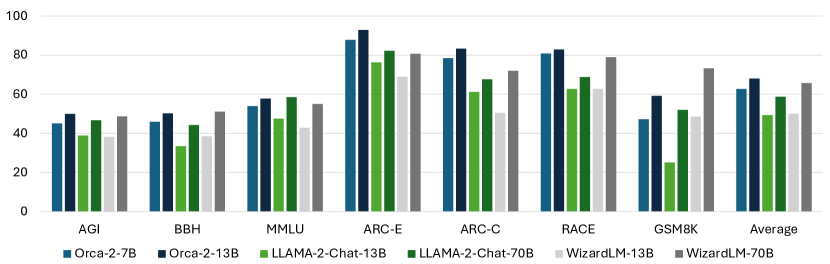
实验结果
研究问题
- RQ1小型 LM 能否学习并应用超越对大模型仿制的推理策略?
- RQ2小型 LM 应如何为给定任务选择最有效的推理策略?
- RQ3使用 Prompt Erasing 的谨慎推理是否能提高零-shot 性能,相较于基于模仿的标准方法?
- RQ4Orca 2 模型在多样化推理基准上如何与更大模型比较?
主要发现
| 模型 | AGI | BBH | DROP | CRASS | RACE | GSM8K |
|---|---|---|---|---|---|---|
| Orca 2-7B | 45.10 | 45.93 | 60.26 | 84.31 | 80.79 | 47.23 |
| Orca 2-7B w/ cautious sm | 43.97 | 42.80 | 69.09 | 88.32 | 75.82 | 55.72 |
| Orca 2-13B | 49.93 | 50.18 | 57.97 | 86.86 | 82.87 | 59.14 |
| Orca 2-13B w/ cautious sm | 48.18 | 50.01 | 70.88 | 87.59 | 79.16 | 65.73 |
| Orca-1-13B | 45.69 | 47.84 | 53.63 | 90.15 | 81.76 | 26.46 |
| LLaMA-2-Chat-13B | 38.85 | 33.6 | 40.73 | 61.31 | 62.69 | 25.09 |
| WizardLM-13B | 38.25 | 38.47 | 45.97 | 67.88 | 62.77 | 48.60 |
| LLaMA-2-Chat-70B | 46.70 | 44.68 | 54.11 | 74.82 | 68.79 | 52.01 |
| WizardLM-70B | 48.73 | 51.08 | 59.62 | 86.13 | 78.96 | 73.24 |
| ChatGPT | 53.13 | 55.38 | 64.39 | 85.77 | 67.87 | 79.38 |
| GPT-4 | 70.40 | 69.04 | 71.59 | 94.53 | 83.08 | 85.52 |
- Orca 2-13B 在零-shot 推理任务上显著优于同等规模的模型。
- Orca 2-13B 在若干复杂推理基准上达到或超过规模为其 5–10 倍的模型。
- 在谨慎系统提示下,Orca 2 在若干数据集上取得显著提升(例如 CRASS、DROP、RACE、GSM8K)。
- 总体而言,Orca 2-13B 的性能与 70B 参数的对手相比具有竞争力,并具备更强的零-shot 推理能力。
- 研究报告在 AGIeval、BBH、DROP、CRASS、RACE、GSM8K 等上的详细零-shot 结果,显示出稳健的推理能力。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。