[论文解读] Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
该论文系统评估自动检测器和人工专家在区分人类创作艺术与 AI 生成的图像在多种风格、模型和对抗条件下的能力,结果显示 Hive 和专家人类提供最强的准确性但互补的弱点。
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today's modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
研究动机与目标
- 评估自动检测器在多种AI模型和风格下区分人类创作艺术与AI生成图像的能力。
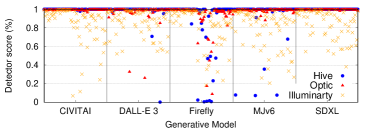
- 评估三种部署的检测器(Hive、Optic、Illuminarty)和两种研究检测器(DIRE、DE-FAKE)在未扰动和扰动图像上的性能。
- 比较三组人工群体(众包工作者、专业艺术家、具备AI检测专业知识的艺术家)在识别AI生成艺术方面的表现。
- 分析对抗性扰动如何影响检测器鲁棒性,并识别人类与自动检测的互补优势。
提出的方法
- 整理一个包含7种风格的280幅真实人类艺术作品以及来自5种扩散模型的350张AI生成图像(含混合和放大变体)的数据集。
- 对图像应用五种检测器(Hive、Optic、Illuminarty、DIRE、DE-FAKE)将图像分类为人类还是AI生成,并报告概率分数。
- 进行三个人类研究(180名众包工作者、4000+名专业艺术家、13名具备AI检测专长的艺术家)在图像分类上使用5分李克特样的决策框架。
- 引入对抗性扰动,包括JPEG压缩、高斯噪声、基于CLIP的扰动,以及Glaze风格扰动,以测试检测器鲁棒性。
- 在扰动条件下评估检测器并分析失败模式,提出联合人机检测方法。

实验结果
研究问题
- RQ1当前的自动检测器和人工专家是否能够在多样化艺术风格下可靠地区分人类艺术与AI生成的图像?
- RQ2对抗性扰动如何影响检测器和人类在识别AI生成艺术中的准确性?
- RQ3自动检测与人工检测的相对优势和劣势是什么,以及联合方法是否能提高鲁棒性?
主要发现
| Detector | ACC (%) | FPR (%) | FNR (%) |
|---|---|---|---|
| Hive | 98.03 | 0.00 | 3.17 |
| Optic | 90.67 | 24.47 | 1.15 |
| Illuminarty | 72.65 | 67.40 | 4.69 |
| DE-FAKE | 50.32 | 41.79 | 56.00 |
| DIRE (a) | 55.40 | 99.29 | 0.86 |
| DIRE (b) | 51.59 | 25.36 | 66.86 |
| Ensemble | 98.75 | 0.48 | 1.71 |
- Hive 在未扰动情况下达到最高的准确率 98.03%,且FPR 为 0%,FNR 为 3.17%。
- 专业艺术家和专家艺术家表现出较高的准确性,但引入了更多的误报;专家艺术家在检测AI图像方面表现良好,但可能将人类艺术误判为AI。
- Optic 和 Illuminarty 的表现低于 Hive,FPR 较高(分别为 24.47% 和 67.40%),FNR 也有差异。
- DIRE 和 DE-FAKE 在艺术数据上的表现较差,准确率约为 50% 或更低。
- 对抗性扰动显著降低 ML 检测器的性能,尤其是特征空间扰动;基于CLIP的扰动和Glaze扰动揭示了不同的漏洞。
- 联合的人类与自动检测团队能实现最佳的总体准确性和鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。