[论文解读] Overcoming catastrophic forgetting with hard attention to the task
本文提出了一种基于任务的硬注意力机制(HAT),为每一层学习几乎二进制的注意力掩码,以在学习新任务的同时保留来自先前任务的信息,显著减少遗忘,并实现模型压缩。
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.
研究动机与目标
- 动机与解决顺序任务学习中的灾难性遗忘问题。
- 开发一个轻量、可训练的硬注意力机制,其条件为任务身份。
- 通过约束梯度更新,使得在不重新训练旧任务的情况下实现并行学习。
- 促进模型稀疏性,并为实际部署提供监控与压缩能力。
提出的方法
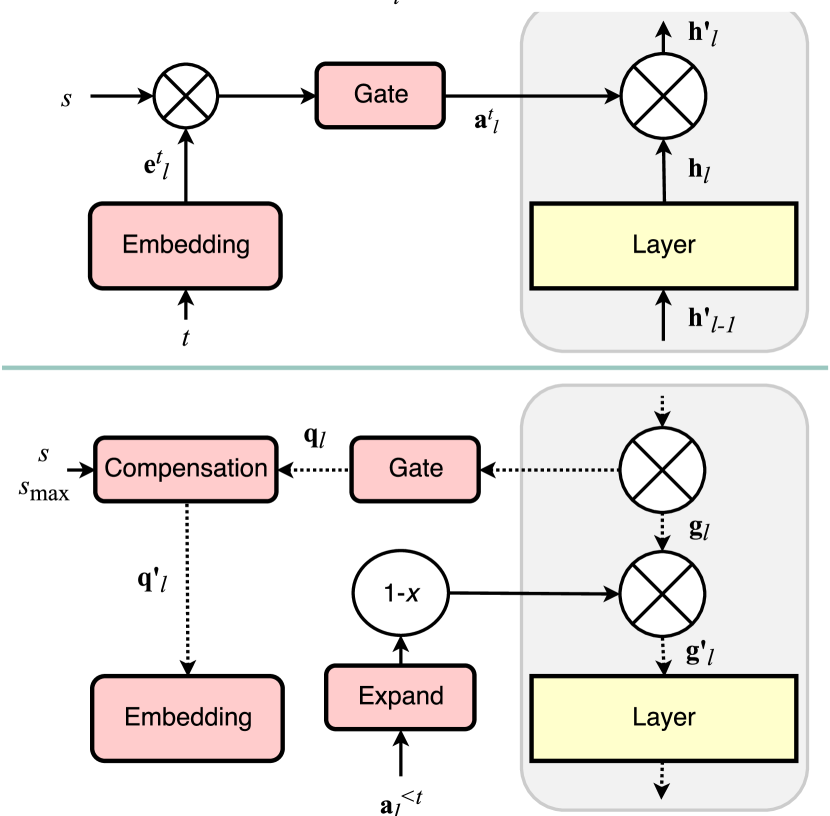
- 引入逐层的硬注意力掩码 a_l^t,由可微分的任务嵌入 e_l^t 通过带缩放参数 s 的 sigmoid 门生成。
- 通过对历史任务取逐元素最大值来计算累积注意力 a^≤t,以保留对过去任务重要的单元。
- 通过逐连接门控项对梯度进行修正,使对对先前任务重要的单元的更新受到惩罚。
- 在训练过程中对门控参数 s 进行退火,以平衡可塑性与稳定性,并执行嵌入梯度补偿以维持有效的学习信号。
- 添加注意力加权的 L1 正则化项,以鼓励跨任务使用单元的稀疏性(可压缩性参数 c)。
- 在8个多样化的图像数据集上使用标准化架构和评估协议,将 HAT 与基线方法(EWC, SI, LWF, LFL, PathNet, PNN, IMM 变体)进行比较。
实验结果
研究问题
- RQ1相对于多任务序列中的最新基线,HAT 在减少灾难性遗忘方面的效果如何?
- RQ2遗忘减少是否对超参数选择与任务顺序具有鲁棒性?
- RQ3HAT 是否能提供监控能力(容量使用、权重重复用)并在不牺牲准确性的前提下支持模型压缩?
- RQ4在不同评估设置(多任务、增量类别、置换数据集)中的表现如何?
主要发现
- 在主要的8任务序列中,HAT 在 t≥2 任务时持续优于基线,达到 ρ≤2 的 -0.02 和 ρ≤8 的 -0.06(相对于基线,遗忘减少幅度为55%-75%)。
- 在8个任务上平均,HAT 将遗忘减少幅度在45%到75%之间,取决于设置,方差低于许多基线。
- HAT 使能在跨任务时监控网络容量使用和权重重复用,并支持将压缩到原始尺寸的1%-21%,同时保持高准确度。
- 在额外的设置中(增量类别、置换 MNIST、拆分 MNIST),HAT 相对于强基线取得显著提升(例如 CIFAR 增量类别:约55% 遗忘减少;置换 MNIST:约52%减少;拆分 MNIST:约80%减少)。
- HAT 的两个超参数(稳定性 s_max 和可压缩性 c)在大范围内表现出鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。