[论文解读] OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models
OWQ 提出对异常值感知的权重量化,在保留弱列高精度的同时对其余部分进行量化,并结合 Weak Column Tuning (WCT) 进行任务特定自适应,达到与 4-bit OPTQ 相当的质量,但约在 3.1-bit 左右,并实现高效微调。
Large language models (LLMs) with hundreds of billions of parameters require powerful server-grade GPUs for inference, limiting their practical deployment. To address this challenge, we introduce the outlier-aware weight quantization (OWQ) method, which aims to minimize LLM's footprint through low-precision representation. OWQ prioritizes a small subset of structured weights sensitive to quantization, storing them in high-precision, while applying highly tuned quantization to the remaining dense weights. This sensitivity-aware mixed-precision scheme reduces the quantization error notably, and extensive experiments demonstrate that 3.1-bit models using OWQ perform comparably to 4-bit models optimized by OPTQ. Furthermore, OWQ incorporates a parameter-efficient fine-tuning for task-specific adaptation, called weak column tuning (WCT), enabling accurate task-specific LLM adaptation with minimal memory overhead in the optimized format. OWQ represents a notable advancement in the flexibility, efficiency, and practicality of LLM optimization literature. The source code is available at https://github.com/xvyaward/owq
研究动机与目标
- 在推理和微调过程中降低大型语言模型的内存和计算开销。
- 识别激活异常值作为量化误差在 LLM 中的关键来源。
- 提出 OWQ 以保护敏感(弱)列并对其余列进行积极量化。
- 引入 WCT 以在 OWQ 量化模型上实现参数高效的任务自适应。
- 在 OPT 与 LLaMA 家族中展示低开销的性能提升。
提出的方法
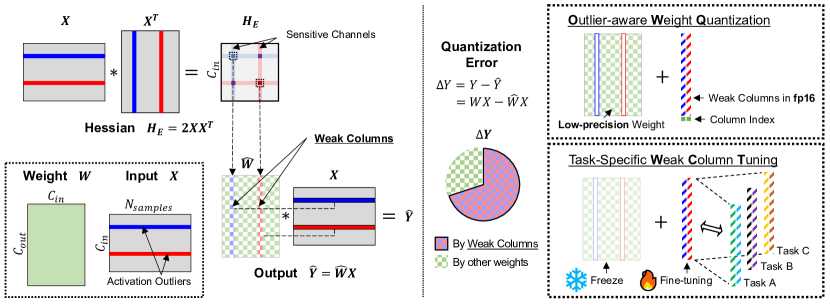
- 通过对 Hessian 对角线和权重扰动幅度计算信道级敏感性来识别弱列(sensitivity_j = lambda_j * ||Delta W_:,j||^2)。
- 将弱列从量化中排除,并对剩余列应用混合精度,通过基于 OPTQ 的技术量化,包括一个带有截断增强的配置搜索。
- 将弱列以 fp16 存储,并为每列存储一个小索引以标记弱列,存储开销极小 (~0.3%)。
- 对非弱列应用 OPTQ,使用包含截断和按通道量化考虑的修改配置搜索。
- 引入 Weak Column Tuning (WCT),在 OWQ 量化后仅对先前识别的弱列进行微调,以在极低内存开销下改善任务自适应能力。
- 通过定制的 OWQ CUDA 内核在真实设备上实现弱列在运行时处理,从而实现加速。
实验结果
研究问题
- RQ1激活异常值在权重量化中是否能被有效考虑以降低 LLM 的量化误差?
- RQ2弱列感知的混合精度方案(OWQ)是否能在较低的实际比特宽度下达到与更高比特基线(如 4-bit OPTQ)相当的性能?
- RQ3WCT 是否能在 OWQ 量化模型上实现有竞争力甚至优于全精度微调的性能,同时保持较低的内存开销?
- RQ4在如 OPT 与 LLaMA 这样的大模型上,OWQ 在推理和微调中的实际开销(时延与存储)是多少?
主要发现
- 3.1-bit OWQ 模型在 WikiText-2 的困惑度及相关指标上与 4-bit OPTQ 的性能相当,覆盖多种模型规模。
- 3.01-bit OWQ 模型进一步提升结果,超过 3-bit OPTQ,在 OPT 与 LLaMA 家族中均有增益。
- 在多个模型规模上,OWQ 相较于 OPTQ 持续提升模型质量,尤其在量化退化更明显的小模型中。
- 弱列感知(保留少量列在高精度下)几乎无额外存储开销 (~0.3%),但带来显著的精度提升。
- WCT 通过显著减少可训练参数数量实现任务特定自适应,且在推理阶段的内存使用远低于完整精度 LoRA,且可达到相同性能。
- 通过定制 CUDA 内核的 OWQ 能保持实用的量化速度(例如在 A100 上对 66B 模型的量化通常在 ~3 小时内完成),尽管进行混合精度处理。
- 在微调场景中,OWQ+WCT 可超越竞争的 PTQ 基微调方法,并在 Vicuna 基准使用基于 GPT-4 的评分实现强劲的 open-LM 任务结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。