[论文解读] PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
PaDeLLM-NER 通过对LLMs中所有标签-提及对进行并行解码来加速NER推断,在输出长度和延迟方面降低,同时保持预测质量。
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
研究动机与目标
- 使用大语言模型降低命名实体识别的生成延迟。
- 在不添加新模块或结构性改动的前提下整合并行解码。
- 在英语和中文NER数据集上维持或超越预测质量。
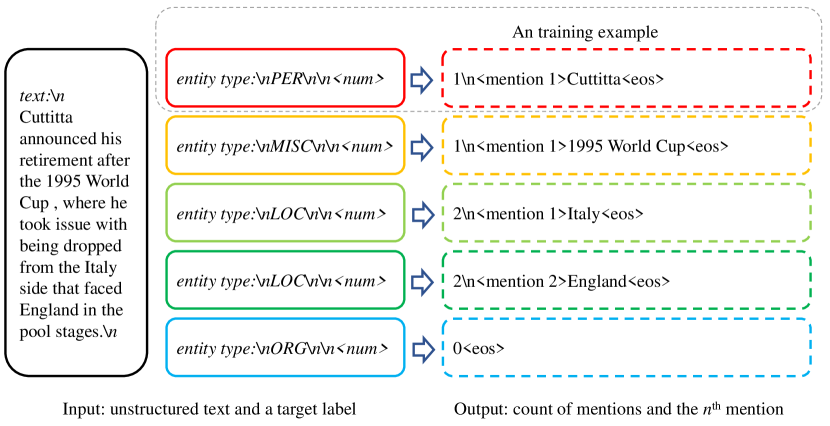
- 重构训练以支持对每个标签计数提及数并识别第n个提及。
- 实现并行解码的标签-提及对的聚合与去重。
提出的方法
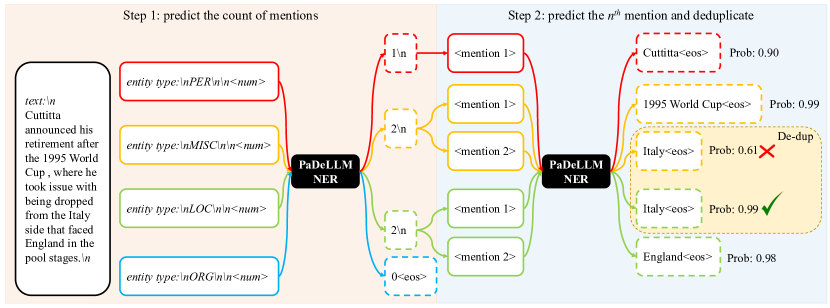
- 重新框架指令微调,使LLMs能够预测每个标签的提及数量以及输入中的第n个提及。
- 在推理阶段,先预测每个标签的提及数量,然后并行生成所有标签-提及对并聚合结果。
- 通过对每个唯一文本保留最高概率的实例来跨标签去重提及。
- 使用两种推理模式:PaDeLLM Multi(多GPU、每序列一个GPU)和 PaDeLLM Batch(单GPU并批处理)。
- 使用计数预测后的序列令牌上跨熵损失进行训练,基于消融发现适当忽略提及跨度令牌。
实验结果
研究问题
- RQ1标签-提及对的并行解码能否在不牺牲准确性的前提下降低NER推断延迟?
- RQ2两步计数和提及策略如何影响英语和中文NER数据集的预测质量?
- RQ3去重对多标签NER输出的精确度、召回率和整体F1值有何影响?
- RQ4PaDeLLM-NER的加速在跨语言的平坦和嵌套NER任务中相较自回归基线有何比较?
主要发现
- 与自回归基线相比,PaDeLLM-NER 的推断延迟显著降低(1.76x 到 10.22x 的加速)。
- 每个样本的平均序列长度降低到自回归方法的约13%,有助于提速。
- PaDeLLM-NER 实现约 84.79 的均值 micro-F1,在若干英语和中文数据集上超过基线(在9个数据集中有4个数据集表现最佳)。
- 两步计数和提及方法使得标签-提及对可以分批并行解码。
- 通过在跨标签中选取最高概率实例进行去重可以提高精确度而对召回率影响不大。
- 该方法在许多数据集上仍与最先进方法具有竞争力,特别在Weibo、Youku和ACE2005上表现出色。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。