[论文解读] ParaTransCNN: Parallelized TransCNN Encoder for Medical Image Segmentation
本文提出 ParaTransCNN,一种并行编码器,将 CNN 和 Transformer 结合,具金字塔结构和通道注意力,用以融合局部与全局特征,实现医疗影像分割,在多数据集上对小器官尤为取得优越结果。
The convolutional neural network-based methods have become more and more popular for medical image segmentation due to their outstanding performance. However, they struggle with capturing long-range dependencies, which are essential for accurately modeling global contextual correlations. Thanks to the ability to model long-range dependencies by expanding the receptive field, the transformer-based methods have gained prominence. Inspired by this, we propose an advanced 2D feature extraction method by combining the convolutional neural network and Transformer architectures. More specifically, we introduce a parallelized encoder structure, where one branch uses ResNet to extract local information from images, while the other branch uses Transformer to extract global information. Furthermore, we integrate pyramid structures into the Transformer to extract global information at varying resolutions, especially in intensive prediction tasks. To efficiently utilize the different information in the parallelized encoder at the decoder stage, we use a channel attention module to merge the features of the encoder and propagate them through skip connections and bottlenecks. Intensive numerical experiments are performed on both aortic vessel tree, cardiac, and multi-organ datasets. By comparing with state-of-the-art medical image segmentation methods, our method is shown with better segmentation accuracy, especially on small organs. The code is publicly available on https://github.com/HongkunSun/ParaTransCNN.
研究动机与目标
- 通过捕捉局部与全局上下文来推动更好的医疗影像分割。
- 开发一个并行编码器,在多尺度融合 CNN 与 Transformer 表征。
- 纳入金字塔结构的 Transformer 与通道注意力模块以实现有效的特征融合。
- 在主动脉血管树、心脏以及多器官分割任务上,与最先进方法进行比较评估。
提出的方法
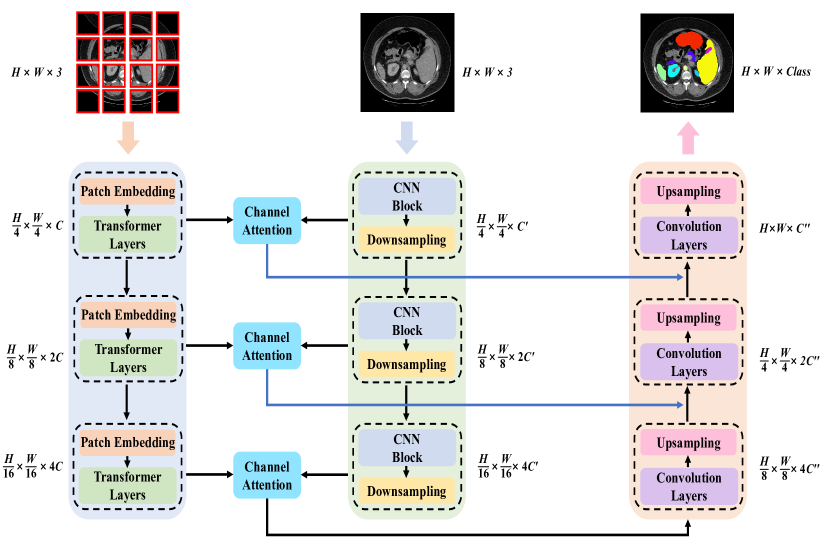
- 双分支编码器:一个 CNN(ResNet)用于局部特征,一个 Transformer(ViT)用于全局特征。
- 金字塔 Transformer 以多分辨率学习全局信息(下采样因子为 4、8、16 的阶段)。
- 采用按阶段的补丁尺寸的补丁嵌入,以对齐 CNN 与 Transformer 的特征。
- 通道注意力模块在每个阶段将 CNN 与 Transformer 特征融合后再传给解码器。
- 类 U-Net 的编码器-解码器架构,带跳连和卷积解码器。
- Dice 损失与交叉熵损失的组合(权重相等,为 0.5)。
![Figure 1: Conceptual comparison of the three most popular models used for medical image segmentation, where (a) classical U-Net [ 39 ] ; (b) Swin U-Net [ 8 ] ; (c) TransUNet [ 10 ] ; (d) Our parallelized TransCNN encoder.](https://ar5iv.labs.arxiv.org/html/2401.15307/assets/x1.png)
实验结果
研究问题
- RQ1带金字塔全局特征的并行 CNN+Transformer 编码器是否能提升相较单分支模型的分割精度?
- RQ2通道注意力能否有效融合多尺度局部与全局特征,实现准确分割、包括小器官?
- RQ3补丁嵌入策略和 Transformer 深度对分割性能有何影响?
- RQ4在多中心医疗影像数据集(AVT、ACDC、Synapse)上,ParaTransCNN 相较于最先进方法的表现如何?
主要发现
- ParaTransCNN 在 AVT、ACDC、Synapse 数据集上实现了最先进或具竞争力的结果。
- 在 AVT 数据集上,ParaTransCNN 达到 DSC = 87.82% 且 95% HD = 4.70,DSC 与 HD 均优于第二名方法。
- 在 ACDC,DSC = 91.31%、HD = 1.16,两个指标均优于若干基线。
- 在 Synapse,DSC = 83.86%、HD = 15.86,胰腺和胃等分段有显著改进。
- 消融研究表明金字塔 Transformer 与通道注意力对达到最佳性能至关重要,而补丁重叠和第四阶段更深的下采样并非有益。
- 质性结果显示比基线更连贯的血管结构和对小器官(胰腺与脾脏)分割更佳。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。