[论文解读] Perception Test: A Diagnostic Benchmark for Multimodal Video Models
本论文介绍 Perception Test,一种真实世界的多模态视频基准,评估记忆、抽象、物理和语义在视频、音频和文本中的表现,涵盖描述性、解释性、预测性和反事实推理,以及密集注释和一个对外公开的测试服务器。
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, SeViLA, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a substantial gap in performance (91.4% vs 46.2%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baseline code, and challenge server are available at https://github.com/deepmind/perception_test
研究动机与目标
- 评估预训练多模态模型在多样感知技能上的迁移性能(零样本、少样本或有限微调)
- 提供密集注释的真实世界视频数据集,以探究记忆、抽象、物理和语义
- 提供公开的训练/验证集分割及一个对外保留测试服务器,以实现健壮的泛化评估
- 通过多种注释类型(跟踪、分段、问答)分析模型偏见和跨任务相关性
提出的方法
- 设计37段经过脚本化的真实世界视频,并引入变体以探测不同技能并避免语言偏见
- 用六种标签对视频进行注释:对象轨迹、点轨迹、时间动作分段、时间声音分段、mc-vQA,以及 grounding vQA
- 定义六项计算任务(跟踪、定位和视频问答)及任务特定的评估指标
- 提供 per-task 基线,使用零样本或少样本设置评估泛化性
- 开源视频、注释与挑战服务器,便于可重复评估
- 在人类基线上的 mc-vQA 以将模型性能置于人类能力的情境中

实验结果
研究问题
- RQ1预训练的多模态视频模型能否在零样本、少样本或有限微调情况下,完成记忆、抽象、物理和语义任务的泛化?
- RQ2多模态模型在不同类型的推理(描述性、解释性、预测性、反事实)和模态(视频、音频、文本)上的表现如何?
- RQ3在一个全面的真实世界诊断基准上,人类表现与最新模型之间存在何种差距?
- RQ4结合注释(跟踪、分段、问答)能提供哪些关于模型偏见与失败模式的洞察?
主要发现
| 任务 | 输出 | 指标 | 基线 | 得分 |
|---|---|---|---|---|
| 对象跟踪 | 框跟踪 | 平均 IoU | SiamFC [8] | 0.67 |
| 点跟踪 | 点跟踪 | 平均 Jaccard | TAP-Net [19] | 0.401 |
| 时序动作定位 | 动作片段列表 | mAP | ActionFormer [57] | 15.56 |
| 时序声音定位 | 声音片段列表 | mAP | ActionFormer [57] | 15.46 |
| 多选视频QA | 答案(1/3) | top-1 准确率 | SeViLA [55] | 46.2 |
| 有定位的视频 QA | 框轨迹列表 | HOTA | MDETR [34] + Stark [52] | 0.1 |
- 11.6k 个真实世界视频(平均 23s)配以密集的多类型注释,便于全面的多模态评估。
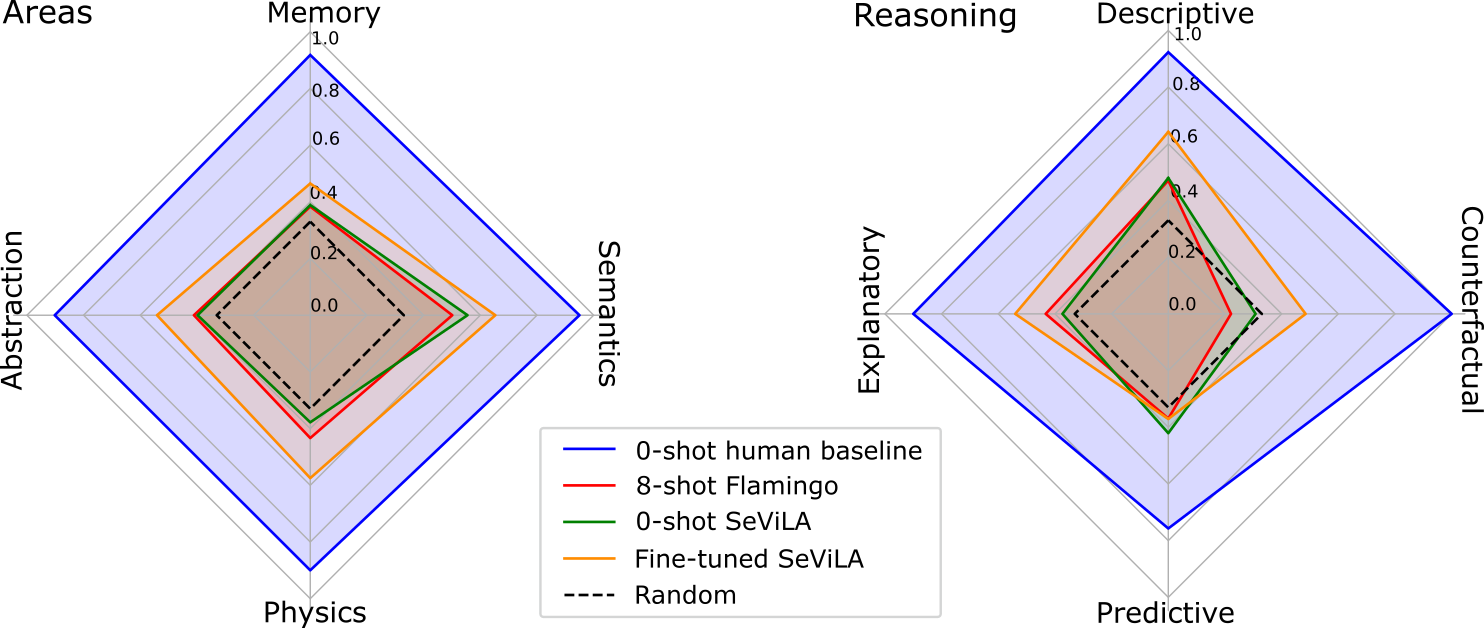
- 人类在 mc-vQA 上达到 91.4%,而最先进模型在零样本/少样本设置中仅为 46.2%,表明仍有较大提升空间。
- Perception Test 揭示模型在记忆、物理和抽象等领域的弱点,在某些任务中常低于简单基线。
- 基线结果显示任务特定的最佳表现:对象跟踪 IoU 0.67、点跟踪 Jaccard 0.401、动作定位 mAP 15.56、声音定位 mAP 15.46、mc-vQA 准确率 46.2、grounded vQA IoU 0.1
- 数据集支持以泛化为导向的评估,提供训练/验证分割和一个对外保留测试服务器以探测跨任务的迁移能力
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。