[论文解读] Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
PSL 将基于 LLM 的高层级计划与基于视觉的 sequencing 及 RL 相结合,以从零开始解决长时程的机器人任务,无需固定技能库。它在 25+ 个任务、最多 10 个阶段的范围内实现了强劲的结果。
Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches. Video results and code at https://mihdalal.github.io/planseqlearn/
研究动机与目标
- 通过利用 LLM 计划来引导 RL,从而在没有固定技能库的情况下实现长时程的机器人任务完成。
- 通过一个基于视觉的排序/序列模块和运动规划,将抽象语言计划与低级控制桥接。
- 通过跨阶段的共享策略和类课程的阶段终止条件来提升学习速度和稳定性。
- 在多项基准测试(25+ 任务,最多 10 个阶段)上,使用纯视觉输入展示最先进的性能。
提出的方法
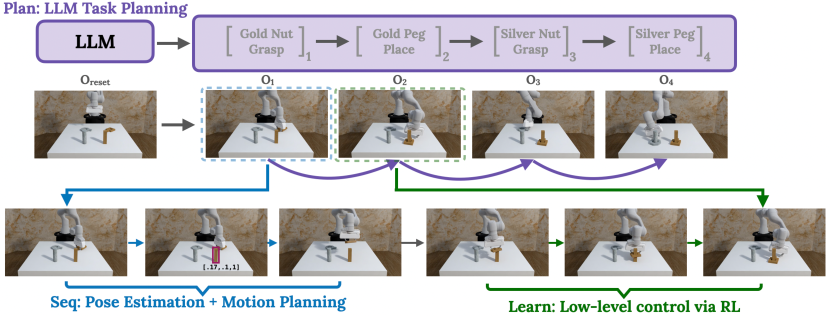
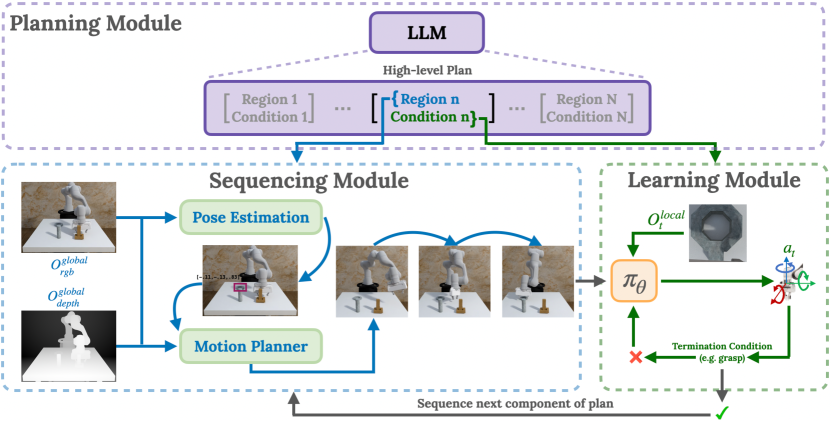
- 通过一个 LLM 计划(Plan)将任务分解为语言生成的区域-阶段对。
- 使用基于视觉的 Sequencing 模块从 RGB-D 观测中估计目标区域,并通过运动规划计算目标姿态(Seq)。
- 训练一个跨所有阶段的单一RL策略,以学习局部交互策略(Learn)。
- 应用阶段终止条件以引导课程学习并防止在执行计划时的犹豫。
- 使用 DRQ-v2 进行训练,并利用局部观测来提升数据效率和泛化。
- 跨阶段共享策略和价值函数,以应对长时程规划误差。
实验结果
研究问题
- RQ1一个大型语言模型是否能够在没有预定义技能库的情况下,为长时程的机器人任务提供有用的零-shot 高层计划?
- RQ2将 LLM 计划与基于视觉的排序以及单一 RL 策略结合,是否能提升长时程任务的学习效率和任务成功率?
- RQ3使用局部观测与阶段终止提示如何影响学习速度以及对姿态噪声的鲁棒性?
- RQ4该 PSL 框架能否扩展到多阶段任务(最多 10 个阶段)在不同基准上的规模化?
主要发现
| 任务 | E2E | RAPS | TAMP | SayCan | PSL |
|---|---|---|---|---|---|
| RS-Bread | 0.52 ± 0.49 | 0.32 ± 0.44 | 0.90 ± 0.01 | 0.93 ± 0.09 | 1.0 ± 0.0 |
| RS-Can | 0.32 ± 0.44 | 0.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.0 ± 0.0 |
| RS-Milk | 0.02 ± 0.04 | 0.00 ± 0.00 | 0.85 ± 0.06 | 0.90 ± 0.05 | 1.0 ± 0.0 |
| RS-Cereal | 0.00 ± 0.00 | 0.00 ± 0.00 | 1.00 ± 0.00 | 0.63 ± 0.09 | 1.0 ± 0.0 |
| RS-NutRound | 0.06 ± 0.13 | 0.00 ± 0.00 | 0.40 ± 0.30 | 0.56 ± 0.25 | 0.98 ± 0.04 |
| RS-NutSquare | 0.02 ± 0.045 | 0.00 ± 0.00 | 0.35 ± 0.20 | 0.27 ± 0.21 | 0.97 ± 0.02 |
- PSL 在四个基准测试上达到超过 85% 的成功率,阶段数高达 10,且仅使用视觉输入。
- 在 Robosuite 的两阶段任务上,PSL 达到 1.0 的成功率,而基线方法落后(E2E、RAPS、SayCan、TAMP),PSL 的平均接近 1.0,而其他方法显著偏低。
- PSL 在多阶段任务上显著超越端到端和分层 RL 基线,在其他方法下降时仍保持高成功率。
- 该方法通过将规划(运动规划)与交互(RL)解耦,有效应对遮挡和高接触的任务。
- 阶段终止提示和跨阶段的共享策略显著提高学习速度和对姿态估计噪声的鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。