[论文解读] PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning
PredRNN 引入时空记忆流和解耦记忆单元(ST-LSTM),并采用课程式训练策略以预测未来帧,在多个数据集上实现有竞争力的性能。
The predictive learning of spatiotemporal sequences aims to generate future images by learning from the historical context, where the visual dynamics are believed to have modular structures that can be learned with compositional subsystems. This paper models these structures by presenting PredRNN, a new recurrent network, in which a pair of memory cells are explicitly decoupled, operate in nearly independent transition manners, and finally form unified representations of the complex environment. Concretely, besides the original memory cell of LSTM, this network is featured by a zigzag memory flow that propagates in both bottom-up and top-down directions across all layers, enabling the learned visual dynamics at different levels of RNNs to communicate. It also leverages a memory decoupling loss to keep the memory cells from learning redundant features. We further propose a new curriculum learning strategy to force PredRNN to learn long-term dynamics from context frames, which can be generalized to most sequence-to-sequence models. We provide detailed ablation studies to verify the effectiveness of each component. Our approach is shown to obtain highly competitive results on five datasets for both action-free and action-conditioned predictive learning scenarios.
研究动机与目标
- 为时空序列激发预测学习,并从历史上下文生成未来帧。
- 用具备记忆增强的循环结构建模时空动态,处理短期和长期依赖。
- 引入训练策略以从上下文帧中学习长期动力学并提升泛化能力。
- 将模型扩展到行动条件下的视频预测并评估其有效性。
提出的方法
- 引入时空记忆流以在之字形路径中跨层传播记忆。
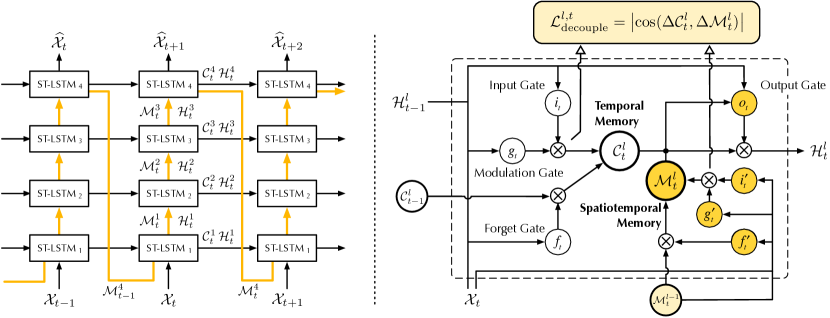
- 提出时空 LSTM(ST-LSTM),具有两个解耦的记忆单元(C 和 M),以分别建模长期和短期动力学。
- 应用记忆解耦损失以促使 C 与 M 之间的特征非冗余。
- 引入反向计划采样以加强从上下文帧学习长期动力学。
- 扩展为带行动融合的行动条件PredRNN,以模拟代理驱动的环境。
- 端到端训练,结合帧重构目标和解耦损失;提供消融验证组件。
![Figure 1: Left: the spatiotemporal memory flow architecture that uses ConvLSTM as the building block. The orange arrows show the deep-in-time path of memory state transitions. Right: the original ConvLSTM network proposed by Shi et al. [ 1 ] .](https://ar5iv.labs.arxiv.org/html/2103.09504/assets/x1.png)
实验结果
研究问题
- RQ1之字形时空记忆流是否能改善跨层信息共享以进行帧预测?
- RQ2将记忆单元解耦为长期和短期分量是否能提升预测建模?
- RQ3所提出的课程式训练(Reverse Scheduled Sampling)是否有助于从上下文帧学习长期动力学?
- RQ4行动条件对时空预测性能有何影响?
- RQ5消融实验是否证实每个组件对总体性能的贡献?
主要发现
- 在五个数据集上实现了无行动和行动条件预测学习场景的最先进性能。
- 提供了详细的消融研究,验证记忆流、带记忆解耦的 ST-LSTM,以及 RSS 训练方案的有效性。
- 在 Moving MNIST、KTH、雷达回波降水预报、Traffic4Cast 和 BAIR 数据集上显示出有竞争力的结果。
- 通过一个行动条件变体扩展该方法,适用于机器人-对象交互场景。
- 公开代码以促进可复现性(论文中包含 GitHub 链接)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。