[论文解读] Principled Weight Initialization for Hypernetworks
本文介绍了用于超网络的超扇初始化,提供基于方差的原理性方案(hyperfan-in 和 hyperfan-out),以保持主网的激活/梯度尺度,从而在稳定性和收敛性方面优于随意初始化。
Hypernetworks are meta neural networks that generate weights for a main neural network in an end-to-end differentiable manner. Despite extensive applications ranging from multi-task learning to Bayesian deep learning, the problem of optimizing hypernetworks has not been studied to date. We observe that classical weight initialization methods like Glorot & Bengio (2010) and He et al. (2015), when applied directly on a hypernet, fail to produce weights for the mainnet in the correct scale. We develop principled techniques for weight initialization in hypernets, and show that they lead to more stable mainnet weights, lower training loss, and faster convergence.
研究动机与目标
- 识别为什么经典权重初始化在为生成主网权重的超网络时会失效。
- 制定针对超网络的基于方差的原理性初始化规则。
- 在理论和经验上表明,hyperfan 初始化可以稳定激活和梯度并改善收敛。
提出的方法
- 利用方差分析推导超网络的 hyperfan-in 和 hyperfan-out 初始化。
- 将超网络建模为主网权重的生成器,并分析前向/反向方差传播。
- 提出 H、h、G、g 层的具体方差公式,以保持主网激活/梯度方差。
- 区分超网络输出仅权重或同时输出权重与偏置的情况。
- 提供使超网权重方差与经典的 fan-in/fan-out 初始化语义对齐的初始化方案。
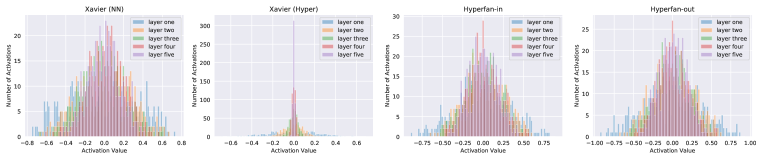
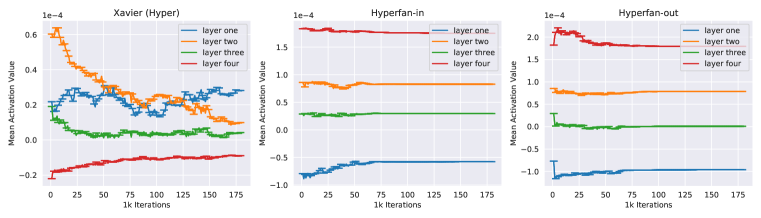
实验结果
研究问题
- RQ1为什么当将经典初始化方案应用于生成主网权重的超网络时,会失败?
- RQ2我们如何初始化超网络,使得主网的激活和梯度在深度增加时保持稳定方差?
- RQ3hyperfan-in 和 hyperfan-out 初始化是否能够在不同的主网结构和任务中实现稳定训练?
主要发现
- 对超网的经典初始化会导致主网激活值爆炸。
- Hyperfan-in 和 hyperfan-out 初始化保持主网方差并实现稳定训练。
- Hyperfan 方法在 MNIST 前馈实验中产生更低的初始损失和更快的收敛。
- 当超网使用 Xavier/Kaiming 失败时,Hyperfan 初始化使训练成为可能(如 CIFAR-10、ImageNet 贝叶斯设置)。
- 两者在多任务下均可与 SGD 一起使用,实践中没有明显偏好。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。