[论文解读] Progressive Neural Architecture Search
PNAS 引入了对 CNN 单元结构的渐进式、代理引导的搜索,在计算速度比以前的基于强化学习的 NAS 方法快多达8倍的情况下达到最先进的准确度。
We propose a new method for learning the structure of convolutional neural networks (CNNs) that is more efficient than recent state-of-the-art methods based on reinforcement learning and evolutionary algorithms. Our approach uses a sequential model-based optimization (SMBO) strategy, in which we search for structures in order of increasing complexity, while simultaneously learning a surrogate model to guide the search through structure space. Direct comparison under the same search space shows that our method is up to 5 times more efficient than the RL method of Zoph et al. (2018) in terms of number of models evaluated, and 8 times faster in terms of total compute. The structures we discover in this way achieve state of the art classification accuracies on CIFAR-10 and ImageNet.
研究动机与目标
- Motivate and reduce the computational cost of neural architecture search (NAS) for CNNs compared to RL and EA approaches.
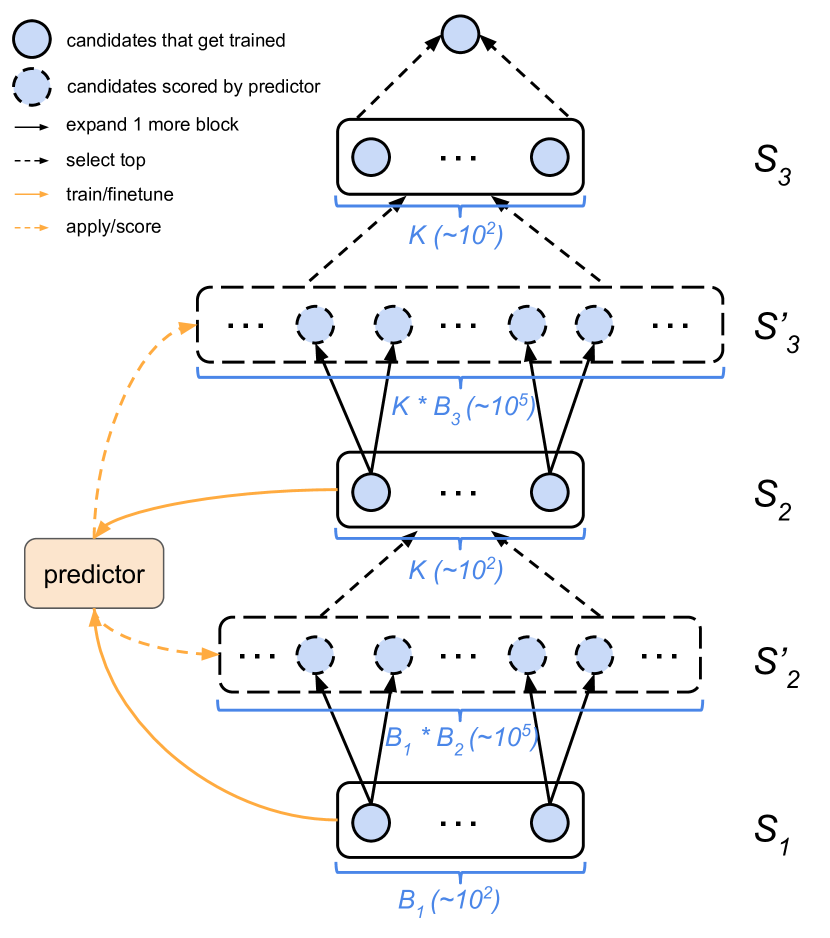
- Propose a progressive, block-wise search over CNN cells combined with a surrogate predictor to guide expansion.
- Demonstrate that the discovered architectures reach state-of-the-art accuracy on CIFAR-10 and ImageNet with lower compute.
- Show that sharing a single cell type and progressively increasing complexity improves search efficiency and transferability.
提出的方法
- Define a hierarchical cell-based search space with B blocks per cell and a fixed set of block operations and inputs.
- Perform progressive search from simple (1-block) cells to deeper (B-block) cells by expanding candidates and predicting performance with a surrogate model.
- Train a population of proxy CNNs built from candidate cells to obtain validation accuracy as supervision.
- Train an ensemble surrogate predictor (MLP or RNN) to rank expanded cells and select top-K for the next generation, updating the predictor with new observed data.
- Construct final CNNs by stacking the best cell type with specified repeats and stride patterns, then train on target datasets (CIFAR-10 and ImageNet).
- Compare efficiency to NAS (RL-based) and random search, reporting model counts, total compute, and top validation accuracy.
![Figure 1: Left : The best cell structure found by our Progressive Neural Architecture Search, consisting of 5 blocks. Right : We employ a similar strategy as [ 41 ] when constructing CNNs from cells on CIFAR-10 and ImageNet. Note that we learn a single cell type instead of distinguishing between Nor](https://ar5iv.labs.arxiv.org/html/1712.00559/assets/x1.png)
实验结果
研究问题
- RQ1Can progressive, surrogate-guided search reduce the number of evaluated models in NAS while maintaining or improving accuracy?
- RQ2Does using a cell-based, progressively complex search space improve efficiency and transferability to larger datasets like ImageNet?
- RQ3How well do surrogate predictors (MLP vs RNN ensembles) rank promising architectures and generalize to larger, unseen cells?
- RQ4What is the practical speedup and accuracy trade-off of PNAS compared with NAS, random search, and Hierarchical EA on CIFAR-10 and ImageNet?
主要发现
| 模型 | B | N | F | 误差 | 参数量 | M1 | E1 | M2 | E2 | 成本 |
|---|---|---|---|---|---|---|---|---|---|---|
| NASNet-A [41] | 5 | 6 | 32 | 3.41 | 3.3M | 20000 | 0.9M | 250 | 13.5M | 21.4-29.3B |
| NASNet-B [41] | 5 | 4 | N/A | 3.73 | 2.6M | 20000 | 0.9M | 250 | 13.5M | 21.4-29.3B |
| NASNet-C [41] | 5 | 4 | N/A | 3.59 | 3.1M | 20000 | 0.9M | 250 | 13.5M | 21.4-29.3B |
| Hier-EA [21] | 5 | 2 | 64 | 3.75 ± 0.12 | 15.7M | 7000 | 5.12M | 0 | 0 | 35.8B |
| AmoebaNet-B [27] | 5 | 6 | 36 | 3.37 ±0.04 | 2.8M | 27000 | 2.25M | 100 | 27M | 63.5B |
| AmoebaNet-A [27] | 5 | 6 | 36 | 3.34 ±0.06 | 3.2M | 20000 | 1.13M | 100 | 27M | 25.2B |
| AmoebaNet-C [27] | 5 | 6 | 36 | 3.35 ±0.05 | 3.2M | 20000 | 1.13M | 100 | 27M | 25.2B |
| PNASNet-5 [PNAS] | 5 | 3 | 48 | 3.41 ±0.09 | 3.2M | 1160 | 0.9M | 0 | 0 | 1.0B |
- PNAS is up to 5x more efficient than the RL NAS method of Zoph et al. (2018) in the number of models evaluated.
- PNAS is up to 8x faster in total compute than the RL NAS method for the same search space.
- The architectures discovered by PNAS achieve state-of-the-art or competitive classification accuracies on CIFAR-10 and ImageNet.
- Using a progressive search with surrogate guidance enables exploring larger, more complex cells than direct full-CNN searches.
- An ML-based surrogate ensemble (especially MLP-ensemble) effectively ranks candidate cells for unseen, larger block counts, improving search efficiency.
- PNASNet-5 outperforms several NAS variants in ImageNet (Mobile and Large settings) while using substantially less compute than AmoebaNet implementations.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。